
Flan-T5_Grammar (Romanian)
Flan-T5-Large is an instruction-tuned language model that treats all NLP tasks as text-to-text problems, excelling at grammar-related tasks like correction, rephrasing, and sentence completion through natural language prompts.
Dataset
I fine-tuned Flan-T5-Large on gec-ro-comments and gec-ro-cna datasets. The split was created by combining train (635 pairs), test (686 pairs), validation (666) from gec-ro-comments and train (1286) from gec-ro-cna to create the training set and test (1234) from gec-ro-cna for testing.
Configuration
- Model = “google/flan-t5-large”
- Learning rate = 5e-5
- Batch size = 4 (for both dataloaders)
- Optimizer = AdamW
- Epochs = 10
- Scheduler = Linear (with warmup = 0.1)
The condition for saving the model is that the test loss, wer, cer must be lower than the previously recorded best values.
Results


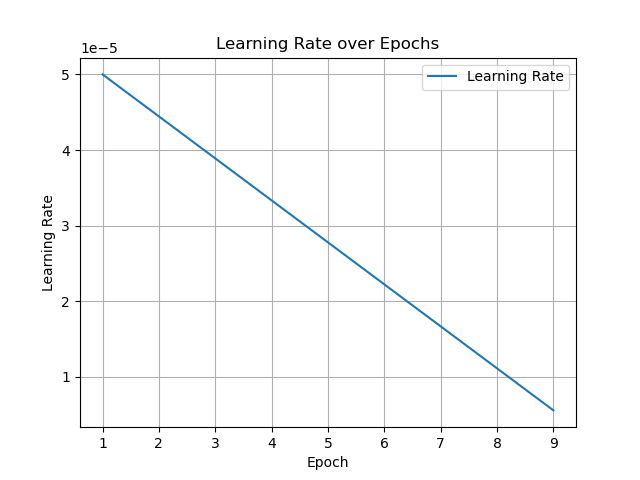
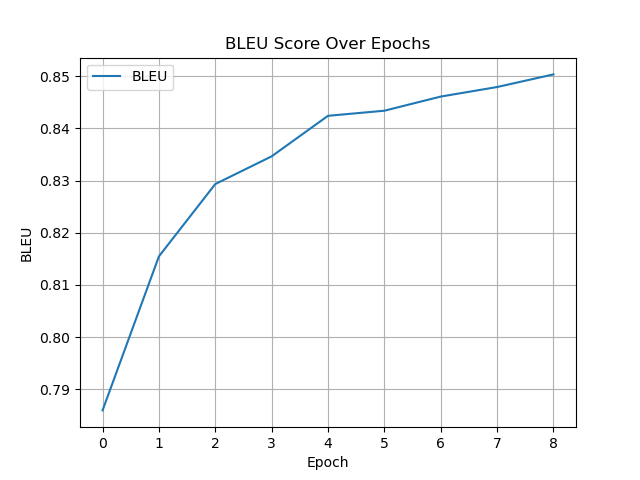

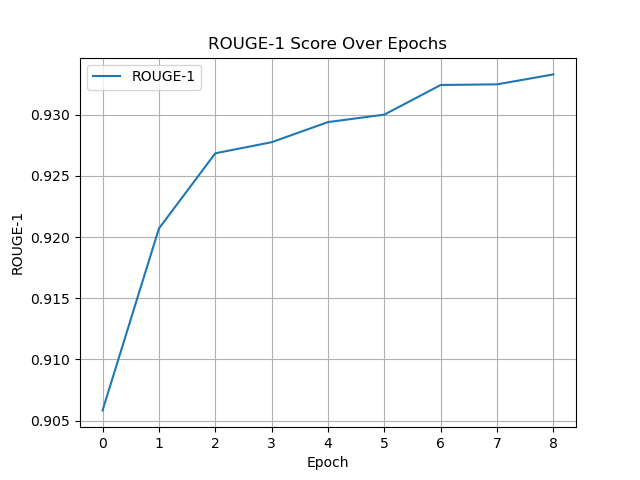
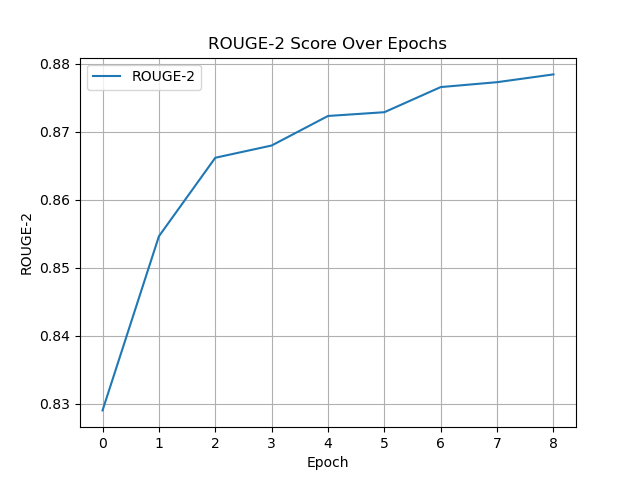

The fine-tuned model was saved at epoch 5 with Test Loss: 0.3151, WER: 0.0893, CER: 0.0304, BLEU: 0.8424, GLEU: 0.8405, ROUGE-1: 0.9294, ROUGE-2: 0.8723, ROUGE-L: 0.9279.
How to use
import torch
from transformers import T5Tokenizer, T5ForConditionalGeneration
# Set device
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# Load model and tokenizer
model_name = "ionut-visan/Flan-T5-Large_Grammar_Ro"
tokenizer = T5Tokenizer.from_pretrained(model_name)
model = T5ForConditionalGeneration.from_pretrained(model_name).to(device)
model.eval()
# Function to correct grammar
def correct_sentence(sentence):
input_text = "grammar: " + sentence
inputs = tokenizer.encode(input_text, return_tensors="pt").to(device)
with torch.no_grad():
outputs = model.generate(inputs, max_length=128, num_beams=4, early_stopping=True)
return tokenizer.decode(outputs[0], skip_special_tokens=True)
# Interactive loop
print("Romanian Grammar Corrector (type 'exit' to quit)")
while True:
user_input = input("\nEnter a sentence to correct: ")
if user_input.lower() == "exit":
print("Exiting. 👋")
break
corrected = correct_sentence(user_input)
print("Corrected:", corrected)
import torch
from transformers import T5Tokenizer, T5ForConditionalGeneration
# Set device
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# Load model and tokenizer
model_name = "ionut-visan/Flan-T5-Large_Grammar_Ro"
tokenizer = T5Tokenizer.from_pretrained(model_name)
model = T5ForConditionalGeneration.from_pretrained(model_name).to(device)
model.eval()
# Function to correct grammar
def correct_sentence(sentence):
input_text = "grammar: " + sentence
inputs = tokenizer.encode(input_text, return_tensors="pt").to(device)
with torch.no_grad():
outputs = model.generate(inputs, max_length=128, num_beams=4, early_stopping=True)
return tokenizer.decode(outputs[0], skip_special_tokens=True)
# Interactive loop
print("Romanian Grammar Corrector (type 'exit' to quit)")
while True:
user_input = input("\nEnter a sentence to correct: ")
if user_input.lower() == "exit":
print("Exiting. 👋")
break
corrected = correct_sentence(user_input)
print("Corrected:", corrected)
Communication
For any questions regarding this model or to explore collaborations on ambitious AI/ML projects, please feel free to contact me at:
- Downloads last month
- 6
Inference Providers
NEW
This model isn't deployed by any Inference Provider.
🙋
Ask for provider support
Model tree for ionut-visan/Flan-T5-Large_Grammar_Ro
Base model
google/flan-t5-large