
gpt-oss-20b-Malaysian-Reasoning-SFT-v0.1
LoRA SFT openai/gpt-oss-20b on initial mesolitica/Malaysian-Reasoning
Ablation on GPT OSS 20B
- Use
kernels-community/vllm-flash-attn3for Flash Attention 3 with Sink. - Multipacking variable length 16384 context length, with global batch size of 8, so global total tokens is 65536.
- All self attention linear layers with rank 16, 32, 64, 128, 256, 512 with alpha multiply by 2.0
- All expert gate up projection and down projection with rank 16, 32, 64, 128, 256, 512 with alpha multiply by 2.0 +
- Selected expert gate up projection and down projection based on square root mean
exp_avg_sq, top 4 selected layers are 3, 2, 18, and 1. + - Liger fused cross entropy.
- 2e-4 learning rate, 50 warmup, 2 epoch only.
+ with the rank of each equal to the total rank divided by the number of active experts, https://thinkingmachines.ai/blog/lora/
We only upload the best model
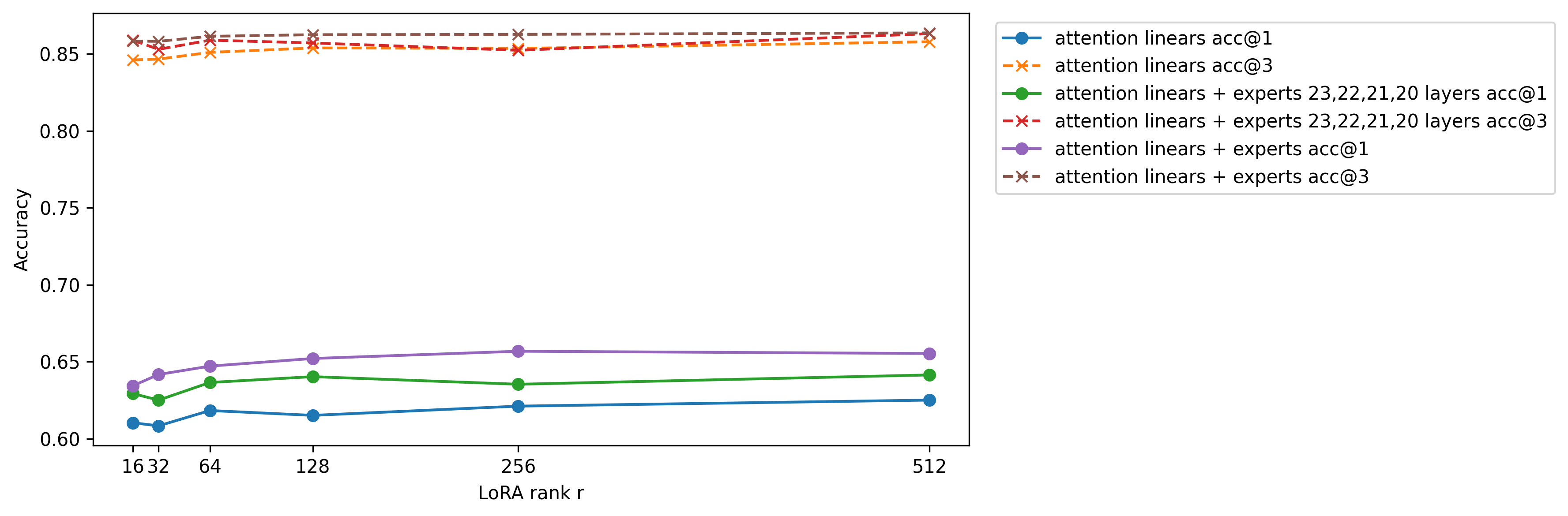
This model repository we only upload the best, only attention linear layers with rank 256 alpha 512.
Source code
Source code at https://github.com/Scicom-AI-Enterprise-Organization/small-ablation/blob/main/malaysian-reasoning
Acknowledgement
Special thanks to https://www.scitix.ai/ for H100 Node!
- Downloads last month
- 83