
Glyph GGUF Models
Model Generation Details
This model was generated using llama.cpp at commit 16724b5b6.
Quantization Beyond the IMatrix
I've been experimenting with a new quantization approach that selectively elevates the precision of key layers beyond what the default IMatrix configuration provides.
In my testing, standard IMatrix quantization underperforms at lower bit depths, especially with Mixture of Experts (MoE) models. To address this, I'm using the --tensor-type option in llama.cpp to manually "bump" important layers to higher precision. You can see the implementation here:
👉 Layer bumping with llama.cpp
While this does increase model file size, it significantly improves precision for a given quantization level.
I'd love your feedback—have you tried this? How does it perform for you?
Click here to get info on choosing the right GGUF model format
Glyph: Scaling Context Windows via Visual-Text Compression
- Repository: https://github.com/thu-coai/Glyph
- Paper: https://arxiv.org/abs/2510.17800
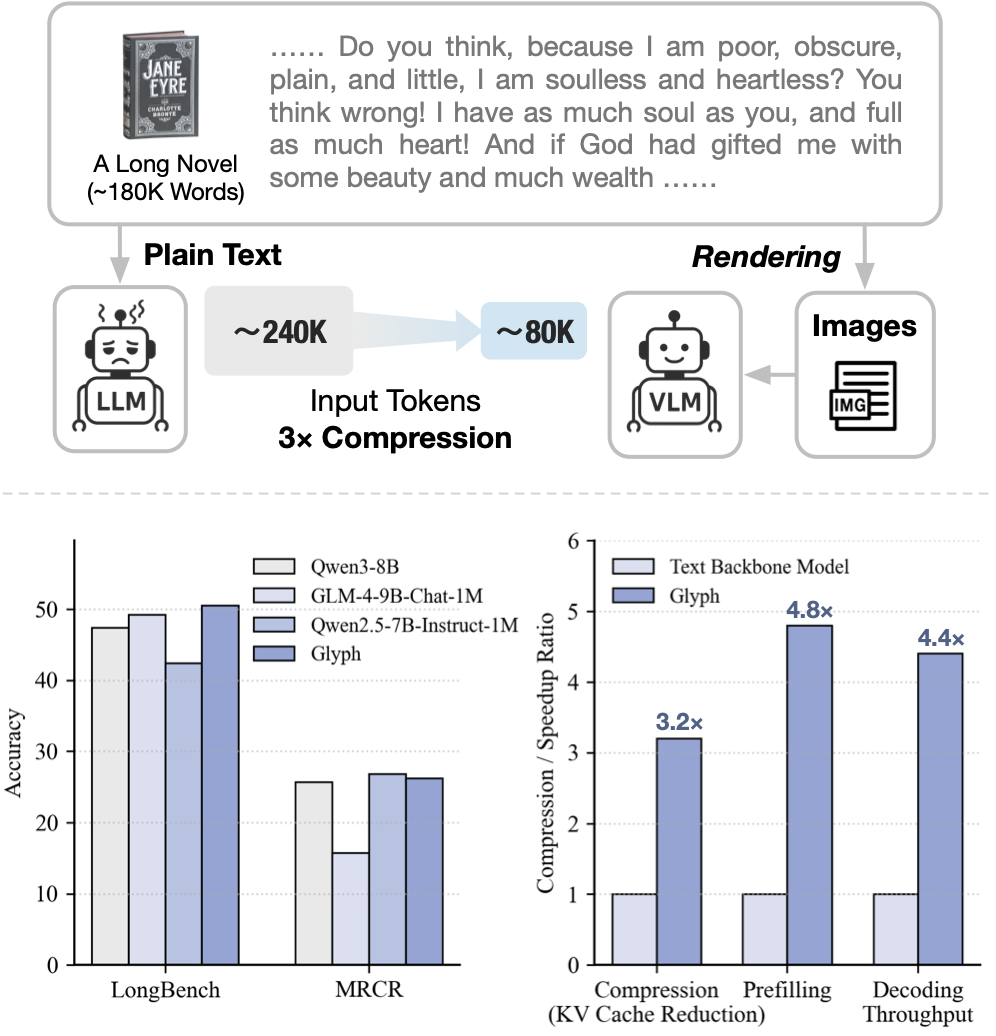
Glyph is a framework for scaling the context length through visual-text compression. Instead of extending token-based context windows, Glyph renders long textual sequences into images and processes them using vision–language models (VLMs). This design transforms the challenge of long-context modeling into a multimodal problem, substantially reducing computational and memory costs while preserving semantic information.
Backbone Model
Our model is built on GLM-4.1V-9B-Base.
Quick Inference
This is a simple example of running single-image inference using the transformers library.
First, install the transformers library:
pip install transformers>=4.57.1
Then, run the following code:
from transformers import AutoProcessor, AutoModelForImageTextToText
import torch
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"url": "https://raw.githubusercontent.com/thu-coai/Glyph/main/assets/Little_Red_Riding_Hood.png"
},
{
"type": "text",
"text": "Who pretended to be Little Red Riding Hood's grandmother"
}
],
}
]
processor = AutoProcessor.from_pretrained("zai-org/Glyph")
model = AutoModelForImageTextToText.from_pretrained(
pretrained_model_name_or_path="zai-org/Glyph",
torch_dtype=torch.bfloat16,
device_map="auto",
)
inputs = processor.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_dict=True,
return_tensors="pt"
).to(model.device)
generated_ids = model.generate(**inputs, max_new_tokens=8192)
output_text = processor.decode(generated_ids[0][inputs["input_ids"].shape[1]:], skip_special_tokens=False)
print(output_text)
See our Github Repo for more detailed usage.
Known Limitations
- Sensitivity to rendering parameters: Glyph’s performance can vary with rendering settings such as resolution, font, and spacing. Since our search procedure adopts a fixed rendering configuration during post-training, the model may not generalize well to unseen or substantially different rendering styles.
- OCR-related challenges: Recognizing fine-grained or rare alphanumeric strings (e.g., UUIDs) remains difficult for visual-language models, especially with ultra-long inputs, sometimes leading to minor character misclassification.
- Limited generalization: The training of Glyph mainly targets long-context understanding, and its capability on broader tasks is yet to be studied.
Citation
If you find our model useful in your work, please cite it with:
@article{cheng2025glyphscalingcontextwindows,
title={Glyph: Scaling Context Windows via Visual-Text Compression},
author={Jiale Cheng and Yusen Liu and Xinyu Zhang and Yulin Fei and Wenyi Hong and Ruiliang Lyu and Weihan Wang and Zhe Su and Xiaotao Gu and Xiao Liu and Yushi Bai and Jie Tang and Hongning Wang and Minlie Huang},
journal={arXiv preprint arXiv:2510.17800},
year={2025}
}
🚀 If you find these models useful
Help me test my AI-Powered Quantum Network Monitor Assistant with quantum-ready security checks:
The full Open Source Code for the Quantum Network Monitor Service available at my github repos ( repos with NetworkMonitor in the name) : Source Code Quantum Network Monitor. You will also find the code I use to quantize the models if you want to do it yourself GGUFModelBuilder
💬 How to test:
Choose an AI assistant type:
TurboLLM(GPT-4.1-mini)HugLLM(Hugginface Open-source models)TestLLM(Experimental CPU-only)
What I’m Testing
I’m pushing the limits of small open-source models for AI network monitoring, specifically:
- Function calling against live network services
- How small can a model go while still handling:
- Automated Nmap security scans
- Quantum-readiness checks
- Network Monitoring tasks
🟡 TestLLM – Current experimental model (llama.cpp on 2 CPU threads on huggingface docker space):
- ✅ Zero-configuration setup
- ⏳ 30s load time (slow inference but no API costs) . No token limited as the cost is low.
- 🔧 Help wanted! If you’re into edge-device AI, let’s collaborate!
Other Assistants
🟢 TurboLLM – Uses gpt-4.1-mini :
- **It performs very well but unfortunatly OpenAI charges per token. For this reason tokens usage is limited.
- Create custom cmd processors to run .net code on Quantum Network Monitor Agents
- Real-time network diagnostics and monitoring
- Security Audits
- Penetration testing (Nmap/Metasploit)
🔵 HugLLM – Latest Open-source models:
- 🌐 Runs on Hugging Face Inference API. Performs pretty well using the lastest models hosted on Novita.
💡 Example commands you could test:
"Give me info on my websites SSL certificate""Check if my server is using quantum safe encyption for communication""Run a comprehensive security audit on my server"- '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code on. This is a very flexible and powerful feature. Use with caution!
Final Word
I fund the servers used to create these model files, run the Quantum Network Monitor service, and pay for inference from Novita and OpenAI—all out of my own pocket. All the code behind the model creation and the Quantum Network Monitor project is open source. Feel free to use whatever you find helpful.
If you appreciate the work, please consider buying me a coffee ☕. Your support helps cover service costs and allows me to raise token limits for everyone.
I'm also open to job opportunities or sponsorship.
Thank you! 😊
- Downloads last month
- 6,310