

| # Mars 5 technical details | |
| While we do not have the time for a proper full writeup of the details of Mars5, its design, training, and implementation, we at least try give a more detailed overview here of how Mars5 works. | |
| ## hubconf object/api | |
| After loading the model with `torch.hub.load`, two objects are returned, a Mars5TTS, and the dataclass of the inference config to use when calling the `mars5.tts()` method. | |
| Concretely, the main methods of the mars5 object are: | |
| ```python | |
| # The init function, called automatically when you initialize the | |
| # model from torch.hub.load(). If you want, you can pass in your | |
| # own custom checkpoints here to initalize the model with your | |
| # own model, tokenizer, etc... | |
| def __init__(self, ar_ckpt, nar_ckpt, device: str = None) -> None: | |
| # ... initialization code ... | |
| # Main text-to-speech function, converting text and a reference | |
| # audio to speech. | |
| def tts(self, text: str, ref_audio: Tensor, ref_transcript: str | None, | |
| cfg: InferenceConfig) -> Tensor: | |
| """ Perform TTS for `text`, given a reference audio `ref_audio` (of shape [sequence_length,], sampled at 24kHz) | |
| which has an associated `ref_transcript`. Perform inference using the inference | |
| config given by `cfg`, which controls the temperature, top_p, etc... | |
| Returns: | |
| - `ar_codes`: (seq_len,) long tensor of discrete coarse code outputs from the AR model. | |
| - `out_wav`: (T,) float output audio tensor sampled at 24kHz. | |
| """ | |
| # Utility function to vocode encodec tokens, if one wishes | |
| # to hear the raw AR model ouput by vocoding the `ar_codes` | |
| # returned above. | |
| def vocode(self, tokens: Tensor) -> Tensor: | |
| """ Vocodes tokens of shape (seq_len, n_q) """ | |
| ``` | |
| ## Model design | |
| Mars 5 follows a two-stage AR-NAR design according to the diagram on the main page. | |
| #### AR component | |
| The AR model follows a Mistral-style decoder-only transformer model to predict Encodec L0 codes (the lowest/most coarse level quantization codes). | |
| Overall, the AR and NAR model is going to predict all 8 codebook entries of the Encodec 6kbps codec. | |
| The AR model design is given below: | |
| 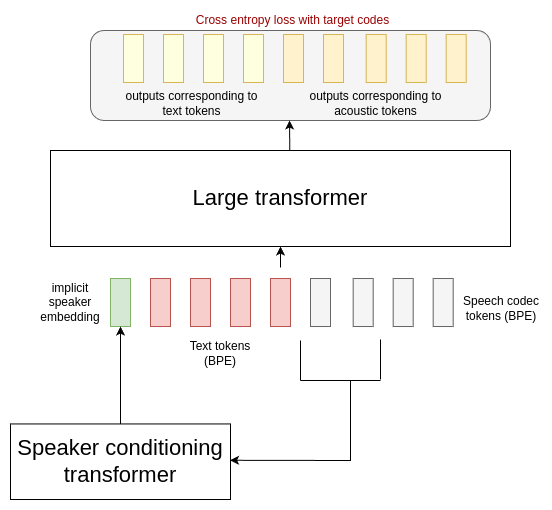 | |
| **Figure**: autoregressive component of Mars 5. During training, the initial 6kbps encodec tokens of the speech are fed through a small encoder-only transformer, producing a single output vector corresponding to an implicit speaker embedding. | |
| This vector is concatenated with learnt embeddings corresponding to the text tokens, and L0 speech tokens, after byte-pair encoding tokenization. | |
| The AR model is trained using the standard next-token prediction task of language models with a cross-entropy loss with the next token, given a smaller weight to text tokens. | |
| During inference, we iteratively sample from the transformer to produce the desiged L0 codes. | |
| When we use a _shallow clone_, then the reference audio is fed into the transcript to make the implicit speaker embedding used in the input sequence. | |
| When we use a _deep clone_, the above is done, but we also concatenate the reference transcript with the desired text, and the reference audio tokens with the input sequence before we start sampling the output. | |
| In pseudocode: | |
| ``` | |
| speaker_embedding <- speaker_conditioning_transformer(ref audio) | |
| if deep_clone: | |
| prompt = concatenate( speaker embedding, reference text, target text, reference L0 speech codes ) | |
| else: | |
| prompt = concatenate( speaker embedding, target text ) | |
| ar output <- autoregressively sample from prompt | |
| ``` | |
| While a deep clone provides a more accurate cloning of the reference speaker identity and prosody, it requires knowledge of the reference transcript and takes longer to do inference. | |
| #### NAR component | |
| After the AR model has predicted the L0 encodec codes, we need a way to predict the remaining 7 codebooks of the 6kbps Encodec codec. | |
| This is what the NAR model is trained to do, using a multinomial diffusion framework. | |
| Concretely, the diffusion process is a discrete DDPM, whereby at each timestep in the diffusion process, it takes in a sequence of `(batch size, sequence length, n_codebooks)` and produces an output categorical distribution over each codebook, i.e. an output of shape `(batch size, sequence length, n_codebooks, 1024)`, since each encodec codebook has 1024 possible values. | |
| The architecture of the model looks as follows: | |
|  | |
| **Figure**: Mars 5 non-autoregressive component. It follows an encoder-decoder transformer architecture, whereby the encoder computes an implicit speaker embedding like the AR model, and concatenates that along with the target to form an input sequence to a transformer encoder. The transformer decoder predicts the distribution of all 8 encodec codebook tokens given a partly noised input at some diffusion timestep `t`. | |
| The encoder and decoder transformers are simple `nn.Transformer` variants with sinusoidal positional embeddings and SwiGLU activations. | |
| A multinomial diffusion manager controls the forward and reference diffusion processes during inference and training according to a cosine diffusion schedule. | |
| Diffusion is performed independently of the sequence length or codebook index. | |
| During training and inference, the L0 codebooks of the input at timestep $t$ are overridden (i.e. not noised in the forward diffusion process) with either the ground truth L0 codes (during training) or the AR model's predictions (during inference). | |
| Like the AR model, the NAR model can perform inference in either a _shallow clone_ way or a _deep clone_ way. | |
| And, like the AR model, the difference between the two is, with a _deep clone_, we concatenate the reference text to the input text sequence, and the reference speech codes (the full values for all 8 codebooks) to the decoder input sequence $x$. | |
| During inference, we then treat the portion of $x$ corresponding to the reference codec codes, and all the AR L0 codes, as 'fixed' and effectively perform diffusion inpainting for the remaining missing codec codes. | |
| The figure below explains what the input to the decoder looks like for a deep clone: | |
|  | |
| This allows us to use diffusion inpainting techniques like [RePaint](https://arxiv.org/abs/2201.09865) to improve the quality of the output at the cost of more inference time. | |
| We've implemented this in the the diffusion config used in the NAR inference code (see it [here](/mars5/diffuser.py)), and you can simply increase the `jump_len` and `jump_n_sample` to greater than 1 to use RePaint inpainting to improve NAR performance. | |