---
base_model: unsloth/qwen2.5-1.5b-instruct-unsloth-bnb-4bit
datasets:
- openai/gsm8k
- HuggingFaceH4/MATH-500
- HuggingFaceH4/aime_2024
language:
- en
library_name: transformers
license: apache-2.0
metrics:
- accuracy
pipeline_tag: text-generation
---
## MOTIF: Modular Thinking via Reinforcement Fine-tuning in LLMs
🔗 Paper link: [Arxiv preprint](https://arxiv.org/abs/2507.02851)
🔗 Github link: [Training and evaluation code](https://github.com/purbeshmitra/MOTIF)
🔗 Link to the trained models: [Hugging Face collection](https://huggingface.co/collections/purbeshmitra/motif-paper-models-686a2f36407bb88f750eef75)
- **Algorithm**: GRPO
- **Training data**: [GSM8K](https://huggingface.co/datasets/openai/gsm8k)
- **Base model**: [unsloth/qwen2.5-3b-instruct-unsloth-bnb-4bit](https://huggingface.co/unsloth/Qwen2.5-3B-Instruct-bnb-4bit)
The INFTYTHINK architecture, shown below, allows multi-round thinking for extended LLM reasoning beyond its context size.

In this work, we propose a GRPO based training method for such a system that allows to calculate the accuracy reward by rolling out trajectories and applying the reward at the first round of inference outcomes. This is depicted as following:

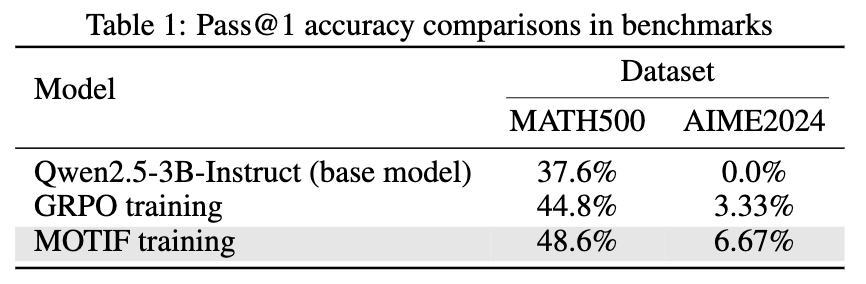
## Results
Our results are shown below:
## Usage
```python
from transformers import AutoModelForCausalLM
from peft import PeftModel
base_model = AutoModelForCausalLM.from_pretrained("unsloth/qwen2.5-1.5b-instruct-unsloth-bnb-4bit")
model = PeftModel.from_pretrained(base_model, "purbeshmitra/vanillaGRPO")
SYSTEM_PROMPT = "You are a helpful assistant. When the user asks a question, you first think about the reasoning process in mind and then provide the user with an answer. The reasoning process and the answer are enclosed within and tags, respectively. In your answer, you also enclose your final answer in the box: \\boxed{}. Therefore, you respond in the following strict format:
reasoning process here answer here ."
```
## Citation
If you find our work useful, consider citing it as:
```bibtex
@article{mitra2025motif,
title={MOTIF: Modular Thinking via Reinforcement Fine-tuning in LLMs},
author={Mitra, Purbesh and Ulukus, Sennur},
journal={arXiv preprint arXiv:2507.02851},
year={2025}
}
```