---
license: apache-2.0
language:
- en
- zh
pipeline_tag: any-to-any
library_name: transformers
---
## Ming-UniVision: Joint Image Understanding and Generation with a Unified Continuous Tokenizer
📑 Technical Report|📖Project Page |🤗 Hugging Face| 🤖 ModelScope| 💾 GitHub
## Key Features
- 🌐 **First Unified Autoregressive MLLM with Continuous Vision Tokens:** Ming-UniVision is the first multimodal large language model that natively integrates continuous visual representations from MingTok into a next-token prediction (NTP) framework—unifying vision and language under a single autoregressive paradigm without discrete quantization or modality-specific heads.
- ⚡ **3.5× Faster Convergence in Joint Vision-Language Training:** The coherent representational space between understanding and generation—enabled by MingTok—reduces optimization conflicts across tasks, leading to dramatically faster convergence during end-to-end multimodal pretraining.
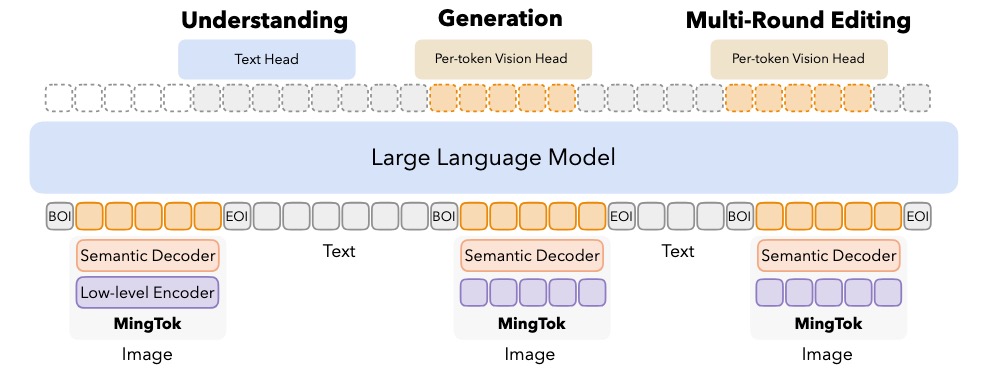
- 🔄 **Multi-Round In-Context Vision Tasks:** Ming-UniVision supports iterative understanding, generation, and editing entirely within the continuous latent space—without the need to decode intermediate states into images, enabling efficient and coherent multimodal reasoning.Users can alternate between asking questions and requesting edits, just like conversing with a human.
**Figure 1: Conceptual comparison and qualitative examples of Ming-UniVision built upon MingTok.**
**Figure 2: Multi-Round image understanding, generation and editing architecture of Ming-UniVision, powered by MingTok.**
## Usage
```python
from mingunivisioninfer import MingUniVisionInfer
model = MingUniVisionInfer("inclusionAI/Ming-UniVision-16B-A3B")
# single round generation
image_gen_prompt = "Please generate the corresponding image based on the description. A cute girl."
messages = [{
"role": "HUMAN",
"content": [{"type": "text", "text": image_gen_prompt},],
}]
output_text = model.generate(messages, max_new_tokens=512, output_image_prefix="a_cute_girl")
model.reset_inner_state()
# single ground understanding
messages = [{
"role": "HUMAN",
"content": [
{"type": "image", "image": "a_cute_girl.png"},
{"type": "text", "text": "Please describe the picture in detail."},
],
}]
output_text = model.generate(messages, max_new_tokens=512)
print(output_text)
model.reset_inner_state()
# multi-round editing
messages = [{
"role": "HUMAN",
"content": [
{"type": "image", "image": "a_cute_girl.png"},
{"type": "text", "text": "Given the edit instruction: Change the color of her cloth to red, please identify the editing region"},
],
}]
output_text = model.generate(messages, max_new_tokens=512, for_edit=True, output_image_prefix="edit_round_0")
messages = [{
"role": "HUMAN",
"content": [
{"type": "text", "text": "Change the color of her cloth to red."},
],
}]
output_text = model.generate(messages, max_new_tokens=512, for_edit=True, output_image_prefix="edit_round_1")
messages = [{
"role": "HUMAN",
"content": [
{"type": "text", "text": "Refine the image for better clarity."},
],
}]
output_text = model.generate(messages, max_new_tokens=512, for_edit=True, output_image_prefix="edit_round_2")
model.reset_inner_state()
# single round text-based conversation
messages = [{
"role": "HUMAN",
"content": [
{"type": "text", "text": "请详细介绍鹦鹉的习性。"},
],
}]
output_text = model.generate(messages, max_new_tokens=512)
print(output_text)
model.reset_inner_state()
```
📌 Tips:
- Image generation: Use descriptive prompts + ``output_image_prefix`` to save output.
- Image understanding: Include "image" and "text" in the same message.
- Image editing: Chain multiple ``generate(..., for_edit=True)`` calls with unique ``output_image_prefix`` names.
- Multi-turn interactions are supported via internal state — call ``model.reset_inner_state()`` to reset.
- Input types: "text" and "image" — flexible order, mixed inputs allowed.
📝 Note (Model Limitations):
- The current model was **trained with only two-turn conversations**, and has not been optimized for alternating rounds of image understanding and generation, although it may generalize to more than two turns during inference. As a result, performance may be limited in complex, multi-modal dialogue scenarios requiring deep contextual reasoning across turns.
- This open-sourced version was **trained using mixed-resolution strategies**: high resolution for image understanding, but lower resolution for image editing and generation. Additionally, large-scale interleaved image-text data was not included during pretraining.
- Due to these factors, *image editing quality and consistency may be suboptimal* compared to fully end-to-end, high-resolution multimodal models. We are actively working on improved versions with unified resolution training and richer interleaved data.
## Performance
### Image Reconstruction
Quantitative Evaluations on Multimodal Benchmarks
Table 1. Quantitative evaluations on MMBench, MMStar, MMMU, MathVista, HallusionBench, AI2D, MM-Vet, OCRBench, and MME.
| Model |
MMB ↑ |
MMS ↑ |
MMMU ↑ |
MathV ↑ |
Hall ↑ |
AI2D ↑ |
MM-Vet ↑ |
OCRBench ↑ |
MME ↑ |
| Understanding Only |
| Emu3-Chat |
58.5 |
- |
31.6 |
- |
- |
- |
37.2 |
687 |
- |
| Qwen2.5-VL-3B |
79.1 |
55.9 |
53.1 |
62.3 |
46.3 |
81.6 |
- |
797 |
2157 |
| Qwen2.5-VL-7B |
83.5 |
63.9 |
58.6 |
68.2 |
52.9 |
83.9 |
67.1 |
864 |
2347 |
| InternVL2.5-4B |
81.1 |
58.3 |
52.3 |
60.5 |
46.3 |
81.4 |
60.6 |
828 |
2338 |
| InternVL2.5-8B |
84.6 |
62.8 |
56.0 |
64.4 |
50.1 |
84.5 |
62.8 |
822 |
2344 |
| DeepSeek-VL2 |
79.6 |
61.3 |
51.1 |
62.8 |
- |
81.4 |
- |
811 |
2253 |
| Unified model, Separate representation |
| Janus-Pro-7B |
79.2 |
- |
41.0 |
- |
- |
- |
50.0 |
- |
- |
| LMFusion |
- |
- |
41.7 |
- |
- |
- |
- |
- |
1603 |
| MetaQuery-L |
78.6 |
- |
53.1 |
- |
- |
- |
63.2 |
- |
- |
| Show-o2-7B |
79.3 |
56.6 |
48.9 |
- |
- |
78.6 |
- |
- |
- |
| BLIP3-o 4B |
78.6 |
- |
46.6 |
- |
- |
- |
60.1 |
- |
2161 |
| BAGEL |
85.0 |
- |
55.3 |
73.1 |
- |
- |
67.2 |
- |
2388 |
| Unified model, Unified representation |
| VILA-U |
- |
- |
- |
- |
- |
- |
33.5 |
- |
1402 |
| TokenFlow-XL |
76.8 |
- |
43.2 |
- |
- |
- |
48.2 |
- |
1922 |
| UniTok |
- |
- |
- |
- |
- |
- |
33.9 |
- |
1448 |
| Harmon-1.5B |
65.5 |
- |
38.9 |
- |
- |
- |
- |
- |
1476 |
| TokLIP |
67.6 |
- |
43.1 |
- |
- |
- |
29.8 |
- |
- |
|
| Ming-UniVision-16B-A3B (Ours) |
78.5 |
63.7 |
40.3 |
66.6 |
47.8 |
82.8 |
64.2 |
724 |
2023 |
Text-to-Image Generation Evaluation
Table 2. Evaluation of text-to-image generation ability on GenEval and DPG-Bench.
† denotes performance obtained by rewritten prompts.
| Method |
Single Obj. ↑ |
Two Obj. ↑ |
Counting ↑ |
Colors ↑ |
Position ↑ |
Color Attri. ↑ |
Overall ↑ |
DPG-Bench ↑ |
| Generation Only |
| LlamaGen |
0.71 |
0.34 |
0.21 |
0.58 |
0.07 |
0.04 |
0.32 |
- |
| PixArt-α |
0.98 |
0.50 |
0.44 |
0.80 |
0.08 |
0.07 |
0.48 |
- |
| SDv2.1 |
0.98 |
0.51 |
0.44 |
0.85 |
0.07 |
0.17 |
0.50 |
- |
| DALL-E 2 |
0.94 |
0.66 |
0.49 |
0.77 |
0.10 |
0.19 |
0.52 |
- |
| Emu3-Gen |
0.98 |
0.71 |
0.34 |
0.81 |
0.17 |
0.21 |
0.54 |
80.60 |
| SDXL |
0.98 |
0.74 |
0.39 |
0.85 |
0.15 |
0.23 |
0.55 |
74.65 |
| DALL-E 3 |
0.96 |
0.87 |
0.47 |
0.83 |
0.43 |
0.45 |
0.67 |
83.50 |
| SD3-Medium |
0.99 |
0.94 |
0.72 |
0.89 |
0.33 |
0.60 |
0.74 |
84.08 |
| Unified model, Separate representation |
| Show-o |
0.95 |
0.52 |
0.49 |
0.82 |
0.11 |
0.28 |
0.53 |
- |
| Ming-Lite-Uni |
0.99 |
0.76 |
0.53 |
0.87 |
0.26 |
0.30 |
0.62 |
- |
| Janus-Pro-1B |
0.98 |
0.82 |
0.51 |
0.89 |
0.65 |
0.56 |
0.73 |
82.63 |
| Janus-Pro-7B |
0.99 |
0.89 |
0.59 |
0.90 |
0.79 |
0.66 |
0.80 |
84.19 |
| Show-o2-7B |
1.00 |
0.87 |
0.58 |
0.92 |
0.52 |
0.62 |
0.76 |
86.14 |
| MetaQuery-L† |
- |
- |
- |
- |
- |
- |
0.78 |
81.10 |
| Blip3-o 4B |
- |
- |
- |
- |
- |
- |
0.81 |
79.36 |
| BAGEL |
0.99 |
0.94 |
0.81 |
0.88 |
0.64 |
0.63 |
0.82 |
- |
| Unified model, Unified representation |
| Harmon-1.5B |
0.99 |
0.86 |
0.66 |
0.85 |
0.74 |
0.48 |
0.79 |
- |
| TokenFlow-XL |
0.95 |
0.60 |
0.41 |
0.81 |
0.16 |
0.24 |
0.55 |
73.38 |
|
| Ming-UniVision-16B-A3B (Ours) |
1.00 |
0.93 |
0.59 |
0.93 |
0.92 |
0.70 |
0.85 |
82.12 |
## Reference
```
@article{huang2025mingunivision,
title={Ming-UniVision: Joint Image Understanding and Generation with a Unified Continuous Tokenizer},
author={Huang, Ziyuan and Zheng, DanDan and Zou, Cheng and Liu, Rui and Wang, Xiaolong and Ji, Kaixiang and Chai, Weilong and Sun, Jianxin and Wang, Libin and Lv, Yongjie and Huang, Taozhi and Liu, Jiajia and Guo, Qingpei and Yang, Ming and Chen, Jingdong and Zhou, Jun},
journal={arXiv preprint arXiv:2510.06590},
year={2025}
}
```