\n**Labeling Method by dataset:** Hybrid (Automated, Human, Synthetic)
\n**Properties:** Includes scanned documents, natural scene ","type":"text"},{"text":"image","type":"highlight"},{"text":"s, charts, tables, infographics, handwritten documents, and synthetic rendered pages in multiple languages and scripts.\n\n### **Evaluation Datasets**\n\nNemotron OCR v2 is evaluated on [OmniDocBench](https://github.com/opendatalab/OmniDocBench), a comprehensive document OCR benchmark covering English, Chinese, and mixed-language content across diverse document categories.\n\n**Data Collection Method by dataset:** Hybrid (Automated, Human, Synthetic)
\n**Labeling Method by dataset:** Hybrid (Automated, Human, Synthetic)
\n**Properties:** Benchmarks include challenging scene ","type":"text"},{"text":"image","type":"highlight"},{"text":"s, documents with varied layouts, and multi-language data.\n\n### **Evaluation Results**\n\nTables below are **reference metrics** from NVIDIA’s benchmark runs (OmniDocBench, SynthDoG). Reproducing them requires datasets and scripts that are **not** checked into this Hugging Face repository.\n\n#### OmniDocBench\n\nNormalized Edit Distance (NED) sample_avg on OmniDocBench (lower = better). Results follow OmniDocBench methodology (empty predictions skipped). All models evaluated in crop mode. Speed measured on a single A100 GPU.\n\n| Model | pages/s | EN | ZH | Mixed | White | Single | Multi | Normal | Rotate90 | Rotate270 | Horizontal |\n| :--- | ---: | ---: | ---: | ---: | ---: | ---: | ---: | ---: | ---: | ---: | ---: |\n| PaddleOCR v5 (server) | 1.2 | 0.027 | 0.037 | 0.041 | 0.031 | 0.035 | 0.064 | 0.031 | 0.116 | 0.897 | 0.027 |\n| OpenOCR (server) | 1.5 | 0.024 | 0.033 | 0.049 | 0.027 | 0.034 | 0.061 | 0.028 | 0.042 | 0.761 | 0.034 |\n| **Nemotron OCR v2 (multilingual)** | **34.7** | **0.048** | **0.072** | **0.142** | **0.061** | **0.049** | **0.117** | **0.062** | **0.109** | **0.332** | **0.372** |\n| *Nemotron OCR v2 (EN)* | *40.7* | *0.038* | *0.830* | *0.437* | *0.348* | *0.282* | *0.572* | *0.353* | *0.232* | *0.827* | *0.893* |\n| EasyOCR | 0.4 | 0.095 | 0.117 | 0.326 | 0.095 | 0.179 | 0.322 | 0.110 | 0.987 | 0.979 | 0.809 |\n| *Nemotron OCR v1* | *39.3* | *0.038* | *0.876* | *0.436* | *0.472* | *0.434* | *0.715* | *0.482* | *0.358* | *0.871* | *0.979* |\n\nColumn key: **pages/s** is throughput using the v2 batched pipeline where measured; **EN** = English, **ZH** = Simplified Chinese, **Mixed** = English/Chinese mixed, **White/Single/Multi** = background type, **Normal/Rotate90/Rotate270/Horizontal** = text orientation.\n\n#### [SynthDoG](https://github.com/clovaai/donut/tree/master/synthdog) Generated Benchmark Data\n\nNormalized Edit Distance (NED) page_avg on [SynthDoG](https://github.com/clovaai/donut/tree/master/synthdog) generated benchmark data (lower = better):\n\n| Language | PaddleOCR (base) | PaddleOCR (specialized) | OpenOCR (server) | Nemotron OCR v1 | *Nemotron OCR v2 (EN)* | **Nemotron OCR v2 (multilingual)** |\n| :--- | ---: | ---: | ---: | ---: | ---: | ---: |\n| English | 0.117 | 0.096 | 0.105 | 0.078 | *0.079* | **0.069** |\n| Japanese | 0.201 | 0.201 | 0.586 | 0.723 | *0.765* | **0.046** |\n| Korean | 0.943 | 0.133 | 0.837 | 0.923 | *0.924* | **0.047** |\n| Russian | 0.959 | 0.163 | 0.950 | 0.564 | *0.632* | **0.043** |\n| Chinese (Simplified) | 0.054 | 0.054 | 0.061 | 0.784 | *0.819* | **0.035** |\n| Chinese (Traditional) | 0.094 | 0.094 | 0.127 | 0.700 | *0.756* | **0.065** |\n\n### **Detailed Performance Analysis**\n\nThe model demonstrates robust multilingual performance on complex layouts, noisy backgrounds, and challenging real-world scenes. Reading order and block detection are powered by the relational module, supporting downstream applications such as chart-to-text, table-to-text, and infographic-to-text extraction.\n\n**Inference**
\n**Acceleration Engine:** PyTorch
\n**Supported Hardware:** H100 PCIe/SXM, A100 PCIe/SXM, L40S, L4, A10G, H200 NVL, B200, RTX PRO 6000 Blackwell Server Edition
\n\n## Ethical Considerations\n\nNVIDIA believes Trustworthy AI is a shared responsibility and we have established policies and practices to enable development for a wide array of AI applications. When downloaded or used in accordance with our terms of service, developers should work with their internal model team to ensure this model meets requirements for the relevant industry and use case and addresses unforeseen product misuse.
\nThe integration of foundation and fine-tuned models into AI systems requires additional testing using use-case-specific data to ensure safe and effective deployment. Following the V-model methodology, iterative testing and validation at both unit and system levels are essential to mitigate risks, meet technical and functional requirements, and ensure compliance with safety and ethical standards before deployment.
\nPlease make sure you have proper rights and permissions for all input ","type":"text"},{"text":"image","type":"highlight"},{"text":" and video content; if ","type":"text"},{"text":"image","type":"highlight"},{"text":" or video includes people, personal health information, or intellectual property, the ","type":"text"},{"text":"image","type":"highlight"},{"text":" or video generated will not blur or maintain proportions of ","type":"text"},{"text":"image","type":"highlight"},{"text":" subjects included.
\nFor more detailed information on ethical considerations for this model, please see the [Explainability](#explainability), [Bias](#bias), [Safety](#safety) & Security, and [Privacy](#privacy) sections below.
\nPlease report security vulnerabilities or NVIDIA AI Concerns [here](https://app.intigriti.com/programs/nvidia/nvidiavdp/detail).\n\n## Bias\n\n| Field | Response |\n| ----- | ----- |\n| Participation considerations from adversely impacted groups [protected classes](https://www.senate.ca.gov/content/protected-classes) in model design and testing | None |\n| Measures taken to mitigate against unwanted bias | None |\n\n\n## Explainability\n\n| Field | Response |\n| ----- | ----- |\n| Intended Task/Domain: | Optical Character Recognition (OCR) with a focus on retrieval application and documents. |\n| Model Type: | Hybrid neural network with convolutional detector, transformer recognizer, and document structure modeling. |\n| Intended Users: | Developers and teams building AI-driven search applications, retrieval-augmented generation (RAG) workflows, multimodal agents, or document intelligence applications. It is ideal for those working with large collections of scanned or photographed documents, including PDFs, forms, and reports. |\n| Output: | Structured OCR results, including detected bounding boxes, recognized text, and confidence scores. |\n| Describe how the model works: | The model first detects text regions in the ","type":"text"},{"text":"image","type":"highlight"},{"text":", then transcribes recognized text, and finally analyzes document structure and reading order. Outputs structured, machine-readable results suitable for downstream search and analysis. |\n| Name the adversely impacted groups this has been tested to deliver comparable outcomes regardless of: | Not Applicable |\n| Technical Limitations & Mitigation: | Performance may vary across languages and scripts. |\n| Verified to have met prescribed NVIDIA quality standards: | Yes |\n| Performance Metrics: | Accuracy (e.g., character error rate), throughput, and latency. |\n| Potential Known Risks: | The model may not always extract or transcribe all text with perfect accuracy, particularly in cases of poor ","type":"text"},{"text":"image","type":"highlight"},{"text":" quality or highly stylized fonts. |\n| Licensing & Terms of Use: | Use of this model is governed by [NVIDIA Open Model License Agreement](https://www.nvidia.com/en-us/agreements/enterprise-software/nvidia-open-model-license/) and the use of the post-processing scripts are licensed under [Apache 2.0](https://www.apache.org/licenses/LICENSE-2.0.txt). |\n\n\n## Privacy\n\n| Field | Response |\n| ----- | ----- |\n| Generatable or reverse engineerable personal data? | No |\n| Personal data used to create this model? | None Known |\n| How often is dataset reviewed? | The dataset is initially reviewed when added, and subsequent reviews are conducted as needed or in response to change requests. |\n| Is there provenance for all datasets used in training? | Yes |\n| Does data labeling (annotation, metadata) comply with privacy laws? | Yes |\n| Is data compliant with data subject requests for data correction or removal, if such a request was made? | No, not possible with externally-sourced data. |\n| Applicable Privacy Policy | https://www.nvidia.com/en-us/about-nvidia/privacy-policy/ |\n| Was consent obtained for any personal data used? | Not Applicable |\n| Was data from user interactions with the AI model (e.g. user input and prompts) used to train the model? | No |\n\n\n## Safety\n\n| Field | Response |\n| ----- | ----- |\n| Model Application Field(s): | Text recognition and structured OCR for multimodal retrieval. Inputs can include natural scene ","type":"text"},{"text":"image","type":"highlight"},{"text":"s, scanned documents, charts, tables, and infographics. |\n| Use Case Restrictions: | Abide by [NVIDIA Open Model License Agreement](https://www.nvidia.com/en-us/agreements/enterprise-software/nvidia-open-model-license/) and the use of the post-processing scripts are licensed under [Apache 2.0](https://www.apache.org/licenses/LICENSE-2.0.txt). |\n| Model and dataset restrictions: | The principle of least privilege (PoLP) is applied, limiting access for dataset generation and model development. Restrictions enforce dataset access only during training, and all dataset license constraints are adhered to. |\n| Describe the life critical impact (if present): | Not applicable. |\n","type":"text"}],"tags":[{"text":"image","type":"highlight"},{"text":", ocr, object recognition, text recognition, layout analysis, ingestion, multilingual, ","type":"text"},{"text":"image","type":"highlight"},{"text":"-to-text, en, zh, ja, ko, ru, license:other, region:us","type":"text"}],"name":[{"text":"nvidia/nemotron-ocr-v2","type":"text"}],"fileName":[{"text":"README.md","type":"text"}]},"authorData":{"_id":"60262b67268c201cdc8b7d43","avatarUrl":"https://cdn-avatars.huggingface.co/v1/production/uploads/65df9200dc3292a8983e5017/Vs5FPVCH-VZBipV3qKTuy.png","fullname":"NVIDIA","name":"nvidia","type":"org","isHf":false,"isHfAdmin":false,"isMod":false,"plan":"plus","followerCount":54672,"isUserFollowing":false}},{"repoId":"68f80acfd05aaf6e9487f711","repoOwnerId":"60262b67268c201cdc8b7d43","isPrivate":false,"type":"model","likes":23,"isReadmeFile":true,"readmeStartLine":18,"updatedAt":1775082133386,"repoName":"nemotron-ocr-v1","repoOwner":"nvidia","tags":"image, ocr, object recognition, text recognition, layout analysis, ingestion, image-to-text, en, license:other, region:us","name":"nvidia/nemotron-ocr-v1","fileName":"README.md","formatted":{"repoName":[{"text":"nemotron-ocr-v1","type":"text"}],"repoOwner":[{"text":"nvidia","type":"text"}],"fileContent":[{"text":"\n# Nemotron OCR v1\n\n## **Model Overview**\n\n\n\n### **Description**\n\nThe Nemotron OCR v1 model is a state-of-the-art text recognition model designed for robust end-to-end optical character recognition (OCR) on complex real-world ","type":"text"},{"text":"image","type":"highlight"},{"text":"s. It integrates three core neural network modules: a detector for text region localization, a recognizer for transcription of detected regions, and a relational model for layout and structure analysis.\n\nThis model is optimized for a wide variety of OCR tasks, including multi-line, multi-block, and natural scene text, and it supports advanced reading order analysis via its relational model component. Nemotron OCR v1 has been developed to be production-ready and commercially usable, with a focus on speed and accuracy on both document and natural scene ","type":"text"},{"text":"image","type":"highlight"},{"text":"s.\n\nThe Nemotron OCR v1 model is part of the NVIDIA NeMo Retriever collection of NIM microservices, which provides state-of-the-art, commercially-ready models and microservices optimized for the lowest latency and highest throughput. It features a production-ready information retrieval pipeline with enterprise support. The models that form the core of this solution have been trained using responsibly selected, auditable data sources. With multiple pre-trained models available as starting points, developers can readily customize them for domain-specific use cases, such as information technology, human resource help assistants, and research & development research assistants.\n\nThis model is ready for commercial use.\n\nWe are excited to announce the open sourcing of this commercial model. For users interested in deploying this model in production environments, it is also available via the model API in NVIDIA Inference Microservices (NIM) at [nemotron-ocr-v1](https://build.nvidia.com/nvidia/nemoretriever-ocr-v1).\n\n### **License/Terms of use**\n\nThe use of this model is governed by the [NVIDIA Open Model License Agreement](https://www.nvidia.com/en-us/agreements/enterprise-software/nvidia-open-model-license/) and the use of the post-processing scripts are licensed under [Apache 2.0](https://www.apache.org/licenses/LICENSE-2.0.txt).\n\n### Team\n\n- Mike Ranzinger\n- Bo Liu\n- Theo Viel\n- Charles Blackmon-Luca\n- Oliver Holworthy\n- Edward Kim\n- Even Oldridge\n\n### Deployment Geography\n\nGlobal\n\n### Use Case\n\nThe **Nemotron OCR v1** model is designed for high-accuracy and high-speed extraction of textual information from ","type":"text"},{"text":"image","type":"highlight"},{"text":"s, making it ideal for powering multimodal retrieval systems, Retrieval-Augmented Generation (RAG) pipelines, and agentic applications that require seamless integration of visual and language understanding. Its robust performance and efficiency make it an excellent choice for next-generation AI systems that demand both precision and scalability across diverse real-world content.\n\n### Release Date\n\n10/23/2025 via https://huggingface.co/nvidia/nemotron-ocr-v1\n\n### References\n\n- Technical blog: https://developer.nvidia.com/blog/approaches-to-pdf-data-extraction-for-information-retrieval/\n\n### **Model Architecture**\n\n**Architecture Type:** Hybrid detector–recognizer with document-level relational modeling\n\nThe Nemotron OCR v1 model integrates three specialized neural components:\n\n- **Text Detector:** Utilizes a RegNetY-8GF convolutional backbone for high-accuracy localization of text regions within ","type":"text"},{"text":"image","type":"highlight"},{"text":"s.\n- **Text Recognizer:** Employs a Transformer-based sequence recognizer to transcribe text from detected regions, supporting variable word and line lengths.\n- **Relational Model:** Applies a multi-layer global relational module to predict logical groupings, reading order, and layout relationships across detected text elements.\n\nAll components are trained jointly in an end-to-end fashion, providing robust, scalable, and production-ready OCR for diverse document and scene ","type":"text"},{"text":"image","type":"highlight"},{"text":"s.\n\n**Network Architecture**: RegNetY-8GF\n\n**Parameter Counts:**\n\n| Component | Parameters |\n|-------------------|-------------|\n| Detector | 45,268,472 |\n| Recognizer | 4,944,346 |\n| Relational model | 2,254,422 |\n| **Total** | 52,467,240 |\n\n### **Input**\n\n| Property | Value |\n|------------------|-------------------|\n| Input Type & Format | ","type":"text"},{"text":"Image","type":"highlight"},{"text":" (RGB, PNG/JPEG, float32/uint8), aggregation level (word, sentence, or paragraph) |\n| Input Parameters (Two-Dimensional) | 3 x H x W (single ","type":"text"},{"text":"image","type":"highlight"},{"text":") or B x 3 x H x W (batch) |\n| Input Range | [0, 1] (float32) or [0, 255] (uint8, auto-converted) |\n| Other Properties | Handles both single ","type":"text"},{"text":"image","type":"highlight"},{"text":"s and batches. Automatic multi-scale resizing for best accuracy. |\n\n### **Output**\n\n| Property | Value |\n|-----------------|-------------------|\n| Output Type | Structured OCR results: a list of detected text regions (bounding boxes), recognized text, and confidence scores |\n| Output Format | Bounding boxes: tuple of floats, recognized text: string, confidence score: float |\n| Output Parameters | Bounding boxes: One-Dimenional (1D) list of bounding box coordinates, recognized text: One-Dimenional (1D) list of strings, confidence score: One-Dimenional (1D) list of floats |\n| Other Properties | Please see the sample output for an example of the model output |\n\n### Sample output\n\n```\nocr_boxes = [[[15.552736282348633, 43.141815185546875],\n [150.00149536132812, 43.141815185546875],\n [150.00149536132812, 56.845645904541016],\n [15.552736282348633, 56.845645904541016]],\n [[298.3145751953125, 44.43315124511719],\n [356.93585205078125, 44.43315124511719],\n [356.93585205078125, 57.34814453125],\n [298.3145751953125, 57.34814453125]],\n [[15.44686508178711, 13.67985725402832],\n [233.15859985351562, 13.67985725402832],\n [233.15859985351562, 27.376562118530273],\n [15.44686508178711, 27.376562118530273]],\n [[298.51727294921875, 14.268900871276855],\n [356.9850769042969, 14.268900871276855],\n [356.9850769042969, 27.790447235107422],\n [298.51727294921875, 27.790447235107422]]]\n\nocr_txts = ['The previous notice was dated',\n '22 April 2016',\n 'The previous notice was given to the company on',\n '22 April 2016']\n\nocr_confs = [0.97730815, 0.98834222, 0.96804602, 0.98499225]\n```\n\nOur AI models are designed and/or optimized to run on NVIDIA GPU-accelerated systems. By leveraging NVIDIA’s hardware (e.g. GPU cores) and software frameworks (e.g., CUDA libraries), the model achieves faster training and inference times compared to CPU-only solutions.\n\n\n### Usage\n\n#### Prerequisites\n\n- **OS**: Linux amd64 with NVIDIA GPU\n- **CUDA**: CUDA Toolkit 12.8 and compatible NVIDIA driver installed (for PyTorch CUDA). Verify with `nvidia-smi`.\n- **Python**: 3.12 (both subpackages require `python = ~3.12`)\n- **Build tools (when building the C++ extension)**:\n - GCC/G++ with C++17 support\n - CUDA toolkit headers (for building CUDA kernels)\n - OpenMP (used by the C++ extension)\n\n\n#### Installation\nThe model requires torch, and the custom code available in this repository.\n\n1. Clone the repository\n\n- Make sure git-lfs is installed (https://git-lfs.com)\n```\ngit lfs install\n```\n- Using https\n```\ngit clone https://huggingface.co/nvidia/nemotron-ocr-v1\n```\n- Or using ssh\n```\ngit clone git@hf.co:nvidia/nemotron-ocr-v1\n```\n\n2. Installation\n\n##### With pip\n\n- Create and activate a Python 3.12 environment (optional)\n\n- Run the following command to install the package:\n\n```bash\ncd nemotron-ocr\npip install hatchling\npip install -v .\n```\n\n##### With docker\n\nRun the example end-to-end without installing anything on the host (besides Docker, docker compose, and NVIDIA Container Toolkit):\n\n- Ensure Docker can see your GPU:\n\n```bash\ndocker run --rm --gpus all nvcr.io/nvidia/pytorch:25.09-py3 nvidia-smi\n```\n\n- From the repo root, bring up the service to run the example against the provided ","type":"text"},{"text":"image","type":"highlight"},{"text":" `ocr-example-image.png`:\n\n```bash\ndocker compose run --rm nemotron-ocr \\\n bash -lc \"python example.py ocr-example-input-1.png --merge-level paragraph\"\n```\n\nThis will:\n- Build an ","type":"text"},{"text":"image","type":"highlight"},{"text":" from the provided `Dockerfile` (based on `nvcr.io/nvidia/pytorch`)\n- Mount the repo at `/workspace`\n- Run `example.py` with model from `checkpoints`\n\nOutput is saved next to your input ","type":"text"},{"text":"image","type":"highlight"},{"text":" as `
\n**Labeling Method:** Hybrid (Automated, Human, Synthetic)
\n**Properties:** Includes scanned documents, natural scene ","type":"text"},{"text":"image","type":"highlight"},{"text":"s, receipts, and business documents.\n\n### **Evaluation Datasets**\n\nThe Nemotron OCR v1 model is evaluated on several NVIDIA internal datasets for various tasks, such as pure OCR, table content extraction, and document retrieval.\n\n**Data Collection Method:** Hybrid (Automated, Human, Synthetic)
\n**Labeling Method:** Hybrid (Automated, Human, Synthetic)
\n**Properties:** Benchmarks include challenging scene ","type":"text"},{"text":"image","type":"highlight"},{"text":"s, documents with varied layouts, and multi-language data.\n\n### **Evaluation Results**\n\nWe benchmarked Nemotron OCR v1 on internal evaluation datasets against PaddleOCR on various tasks, such as pure OCR (Character Error Rate), table content extraction (TEDS), and document retrieval (Recall@5).\n\n| Metric | Nemotron OCR v1 | PaddleOCR | Net change |\n|-------------------------------------------|--------------------|-----------|-----------------|\n| Character Error Rate | 0.1633 | 0.2029 | -19.5% ✔️ |\n| Bag-of-character Error Rate | 0.0453 | 0.0512 | -11.5% ✔️ |\n| Bag-of-word Error Rate | 0.1203 | 0.2748 | -56.2% ✔️ |\n| Table Extraction TEDS | 0.781 | 0.781 | 0.0% ⚖️ |\n| Public Earnings Multimodal Recall@5 | 0.779 | 0.775 | +0.5% ✔️ |\n| Digital Corpora Multimodal Recall@5 | 0.901 | 0.883 | +2.0% ✔️ |\n\n### **Detailed Performance Analysis**\n\nThe model demonstrates robust performance on complex layouts, noisy backgrounds, and challenging real-world scenes. Reading order and block detection are powered by the relational module, supporting downstream applications such as chart-to-text, table-to-text, and infographic-to-text extraction.\n\n\n\n## Ethical Considerations\n\nNVIDIA believes Trustworthy AI is a shared responsibility and we have established policies and practices to enable development for a wide array of AI applications. When downloaded or used in accordance with our terms of service, developers should work with their internal model team to ensure this model meets requirements for the relevant industry and use case and addresses unforeseen product misuse.
\nFor more detailed information on ethical considerations for this model, please see the Explainability, Bias, Safety & Security, and Privacy sections below.
\nPlease report security vulnerabilities or NVIDIA AI Concerns [here](https://app.intigriti.com/programs/nvidia/nvidiavdp/detail).\n\n## Bias\n\n| Field | Response |\n| ----- | ----- |\n| Participation considerations from adversely impacted groups [protected classes](https://www.senate.ca.gov/content/protected-classes) in model design and testing | None |\n| Measures taken to mitigate against unwanted bias | None |\n\n\n## Explainability\n\n| Field | Response |\n| ----- | ----- |\n| Intended Task/Domain: | Optical Character Recognition (OCR) with a focus on retrieval application and documents. |\n| Model Type: | Hybrid neural network with convolutional detector, transformer recognizer, and document structure modeling. |\n| Intended Users: | Developers and teams building AI-driven search applications, retrieval-augmented generation (RAG) workflows, multimodal agents, or document intelligence applications. It is ideal for those working with large collections of scanned or photographed documents, including PDFs, forms, and reports. |\n| Output: | Structured OCR results, including detected bounding boxes, recognized text, and confidence scores. |\n| Describe how the model works: | The model first detects text regions in the ","type":"text"},{"text":"image","type":"highlight"},{"text":", then transcribes recognized text, and finally analyzes document structure and reading order. Outputs structured, machine-readable results suitable for downstream search and analysis. |\n| Name the adversely impacted groups this has been tested to deliver comparable outcomes regardless of: | Not Applicable |\n| Technical Limitations: | This model version supports English only. |\n| Verified to have met prescribed NVIDIA quality standards: | Yes |\n| Performance Metrics: | Accuracy (e.g., character error rate), throughput, and latency. |\n| Potential Known Risks: | The model may not always extract or transcribe all text with perfect accuracy, particularly in cases of poor ","type":"text"},{"text":"image","type":"highlight"},{"text":" quality or highly stylized fonts. |\n| Licensing & Terms of Use: | Use of this model is governed by [NVIDIA Open Model License Agreement](https://www.nvidia.com/en-us/agreements/enterprise-software/nvidia-open-model-license/) and the use of the post-processing scripts are licensed under [Apache 2.0](https://www.apache.org/licenses/LICENSE-2.0.txt). |\n\n\n## Privacy\n\n| Field | Response |\n| ----- | ----- |\n| Generatable or reverse engineerable personal data? | No |\n| Personal data used to create this model? | None Known |\n| How often is dataset reviewed? | The dataset is initially reviewed when added, and subsequent reviews are conducted as needed or in response to change requests. |\n| Is there provenance for all datasets used in training? | Yes |\n| Does data labeling (annotation, metadata) comply with privacy laws? | Yes |\n| Is data compliant with data subject requests for data correction or removal, if such a request was made? | No, not possible with externally-sourced data. |\n| Applicable Privacy Policy | https://www.nvidia.com/en-us/about-nvidia/privacy-policy/ |\n\n\n## Safety\n\n| Field | Response |\n| ----- | ----- |\n| Model Application Field(s): | Text recognition and structured OCR for multimodal retrieval. Inputs can include natural scene ","type":"text"},{"text":"image","type":"highlight"},{"text":"s, scanned documents, charts, tables, and infographics. |\n| Use Case Restrictions: | Abide by [NVIDIA Open Model License Agreement](https://www.nvidia.com/en-us/agreements/enterprise-software/nvidia-open-model-license/) and the use of the post-processing scripts are licensed under [Apache 2.0](https://www.apache.org/licenses/LICENSE-2.0.txt). |\n| Model and dataset restrictions: | The principle of least privilege (PoLP) is applied, limiting access for dataset generation and model development. Restrictions enforce dataset access only during training, and all dataset license constraints are adhered to. |\n| Describe the life critical impact (if present): | Not applicable. |","type":"text"}],"tags":[{"text":"image","type":"highlight"},{"text":", ocr, object recognition, text recognition, layout analysis, ingestion, ","type":"text"},{"text":"image","type":"highlight"},{"text":"-to-text, en, license:other, region:us","type":"text"}],"name":[{"text":"nvidia/nemotron-ocr-v1","type":"text"}],"fileName":[{"text":"README.md","type":"text"}]},"authorData":{"_id":"60262b67268c201cdc8b7d43","avatarUrl":"https://cdn-avatars.huggingface.co/v1/production/uploads/65df9200dc3292a8983e5017/Vs5FPVCH-VZBipV3qKTuy.png","fullname":"NVIDIA","name":"nvidia","type":"org","isHf":false,"isHfAdmin":false,"isMod":false,"plan":"plus","followerCount":54672,"isUserFollowing":false}},{"repoId":"692edbbe20c9fd399bf46689","repoOwnerId":"687e32b78384678a69e933f8","isPrivate":false,"type":"model","likes":4,"isReadmeFile":true,"readmeStartLine":12,"updatedAt":1767541803689,"repoName":"Ovis_Image_7B_fp8","repoOwner":"qpqpqpqpqpqp","tags":"image generation, comfyui, text-to-image, en, zh, base_model:AIDC-AI/Ovis-Image-7B, base_model:finetune:AIDC-AI/Ovis-Image-7B, license:apache-2.0, region:us","name":"qpqpqpqpqpqp/Ovis_Image_7B_fp8","fileName":"README.md","formatted":{"repoName":[{"text":"Ovis_Image_7B_fp8","type":"text"}],"repoOwner":[{"text":"qpqpqpqpqpqp","type":"text"}],"fileContent":[{"text":"\n
The world's first fp8 quants of Ovis ","type":"text"},{"text":"Image","type":"highlight"},{"text":" 7B!\n  Enjoy!\n
Enjoy!\n
","type":"text"}],"tags":[{"text":"image","type":"highlight"},{"text":" generation, comfyui, text-to-image, en, zh, base_model:AIDC-AI/Ovis-Image-7B, base_model:finetune:AIDC-AI/Ovis-Image-7B, license:apache-2.0, region:us","type":"text"}],"name":[{"text":"qpqpqpqpqpqp/Ovis_Image_7B_fp8","type":"text"}],"fileName":[{"text":"README.md","type":"text"}]},"authorData":{"_id":"687e32b78384678a69e933f8","avatarUrl":"https://cdn-avatars.huggingface.co/v1/production/uploads/687e32b78384678a69e933f8/w2EWMTq4AqAh8PyNI3htR.jpeg","fullname":"❔","name":"qpqpqpqpqpqp","type":"user","isPro":false,"isHf":false,"isHfAdmin":false,"isMod":false,"followerCount":14,"isUserFollowing":false}},{"repoId":"68f103308b1ec88bf329c0af","repoOwnerId":"60262b67268c201cdc8b7d43","isPrivate":false,"type":"model","likes":2,"isReadmeFile":true,"readmeStartLine":16,"updatedAt":1773834398165,"repoName":"nemotron-page-elements-v3","repoOwner":"nvidia","tags":"image, detection, pdf, ingestion, yolox, object-detection, en, arxiv:2107.08430, license:other, region:us","name":"nvidia/nemotron-page-elements-v3","fileName":"README.md","formatted":{"repoName":[{"text":"nemotron-page-elements-v3","type":"text"}],"repoOwner":[{"text":"nvidia","type":"text"}],"fileContent":[{"text":"# Nemotron Page Element v3\n\n## Model Overview\n\n\n*Preview of the model output on the example ","type":"text"},{"text":"image","type":"highlight"},{"text":".*\n\n### Description\n\nThe **Nemotron Page Elements v3** model is a specialized object detection model designed to identify and extract elements from document pages. While the underlying technology builds upon work from [Megvii Technology](https://github.com/Megvii-BaseDetection/YOLOX), we developed our own base model through complete retraining rather than using pre-trained weights. YOLOX is an anchor-free version of YOLO (You Only Look Once), this model combines a simpler architecture with enhanced performance. The model is trained to detect **tables**, **charts**, **infographics**, **titles**, **header/footers** and **texts** in documents.\n\nThis model supersedes the [nemotron-page-elements](https://build.nvidia.com/nvidia/nemoretriever-page-elements-v2) model and is a part of the NVIDIA Nemotron family of NIM microservices specifically for object detection and multimodal extraction of enterprise documents.\n\nThis model is ready for commercial/non-commercial use. \n\nWe are excited to announce the open sourcing of this commercial model. For users interested in deploying this model in production environments, it is also available via the model API in NVIDIA Inference Microservices (NIM) at [nemoretriever-page-elements-v2](https://build.nvidia.com/nvidia/nemoretriever-page-elements-v2).\n\n### License/Terms of use\n\nThe use of this model is governed by the [NVIDIA Open Model License Agreement](https://www.nvidia.com/en-us/agreements/enterprise-software/nvidia-open-model-license/) and the use of the post-processing scripts are licensed under [Apache 2.0](https://www.apache.org/licenses/LICENSE-2.0.txt).\n\n### Team\n\n- Theo Viel\n- Bo Liu\n- Darragh Hanley\n- Even Oldridge\n\nCorrespondence to Theo Viel (tviel@nvidia.com) and Bo Liu (boli@nvidia.com)\n\n### Deployment Geography\n\nGlobal\n\n### Use Case\n\nThe **Nemotron Page Elements v3** model is designed for automating extraction of text, charts, tables, infographics etc in enterprise documents. It can be used for document analysis, understanding and processing. Key applications include:\n- Enterprise document extraction, embedding and indexing\n- Augmenting Retrieval Augmented Generation (RAG) workflows with multimodal retrieval\n- Data extraction from legacy documents and reports\n\n### Release Date\n\n10/23/2025 via https://huggingface.co/nvidia/nemotron-page-elements-v3\n\n### References\n\n- YOLOX paper: https://arxiv.org/abs/2107.08430\n- YOLOX repo: https://github.com/Megvii-BaseDetection/YOLOX\n- Previous version of the Page Element model: https://build.nvidia.com/nvidia/nemoretriever-page-elements-v2\n- Technical blog: https://developer.nvidia.com/blog/approaches-to-pdf-data-extraction-for-information-retrieval/\n\n### Model Architecture\n\n**Architecture Type**: YOLOX Enjoy!\n\n**Network Architecture**: DarkNet53 Backbone \\+ FPN Decoupled head (one 1x1 convolution \\+ 2 parallel 3x3 convolutions (one for the classification and one for the bounding box prediction). YOLOX is a single-stage object detector that improves on Yolo-v3.
\n**This model was developed based on the Yolo architecture**
\n**Number of model parameters**: 5.4e7
\n\n### Input\n\n**Input Type(s)**: ","type":"text"},{"text":"Image","type":"highlight"},{"text":"
\n**Input Format(s)**: Red, Green, Blue (RGB)
\n**Input Parameters**: Two-Dimensional (2D)
\n**Other Properties Related to Input**: ","type":"text"},{"text":"Image","type":"highlight"},{"text":" size resized to `(1024, 1024)`\n\n### Output\n\n**Output Type(s)**: Array
\n**Output Format**: A dictionary of dictionaries containing `np.ndarray` objects. The outer dictionary has entries for each sample (page), and the inner dictionary contains a list of dictionaries, each with a bounding box (`np.ndarray`), class label, and confidence score for that page.
\n**Output Parameters**: One-Dimensional (1D)
\n**Other Properties Related to Output**: The output contains bounding boxes, detection confidence scores, and object classes (chart, table, infographic, title, text, headers and footers). The thresholds used for non-maximum suppression are `conf_thresh=0.01` and `iou_thresh=0.5`.
\n**Output Classes**:
\n * Table\n * Data structured in rows and columns\n * Chart\n * Specifically bar charts, line charts, or pie charts\n * Infographic\n * Visual representations of information that is more complex than a chart, including diagrams and flowcharts\n * Maps are _not_ considered infographics\n * Title\n * Titles can be section titles, or table/chart/infographic titles\n * Header/footer\n * Page headers and footers\n * Text\n * Texts are regions of one or more text paragraphs, or standalone text not belonging to any of the classes above\n\nOur AI models are designed and/or optimized to run on NVIDIA GPU-accelerated systems. By leveraging NVIDIA’s hardware (e.g. GPU cores) and software frameworks (e.g., CUDA libraries), the model achieves faster training and inference times compared to CPU-only solutions.\n\n### Usage\n\nThe model requires torch, and the custom code available in this repository.\n\n1. Clone the repository\n\n- Make sure git-lfs is installed (https://git-lfs.com)\n```\ngit lfs install\n```\n- Using https\n```\ngit clone https://huggingface.co/nvidia/nemotron-page-elements-v3\n```\n- Or using ssh\n```\ngit clone git@hf.co:nvidia/nemotron-page-elements-v3\n```\nOptional:\nThis can be installed as a package using pip\n```\ncd nemotron-page-elements-v3\npip install -e .\n```\n2. Run the model using the following code:\n\n```\nimport torch\nimport numpy as np\nimport matplotlib.pyplot as plt\nfrom PIL import ","type":"text"},{"text":"Image","type":"highlight"},{"text":"\n\nfrom nemotron_page_elements_v3.model import define_model\nfrom nemotron_page_elements_v3.utils import plot_sample, postprocess_preds_page_element, reformat_for_plotting\n\n# Load ","type":"text"},{"text":"image","type":"highlight"},{"text":"\npath = \"./example.png\"\nimg = ","type":"text"},{"text":"Image","type":"highlight"},{"text":".open(path).convert(\"RGB\")\nimg = np.array(img)\n\n# Load model\nmodel = define_model(\"page_element_v3\")\n\n# Inference\nwith torch.inference_mode():\n x = model.preprocess(img)\n preds = model(x, img.shape)[0]\n\nprint(preds)\n\n# Post-processing\nboxes, labels, scores = postprocess_preds_page_element(preds, model.thresholds_per_class, model.labels)\n\n# Plot\nboxes_plot, confs = reformat_for_plotting(boxes, labels, scores, img.shape, model.num_classes)\n\nplt.figure(figsize=(15, 10))\nplot_sample(img, boxes_plot, confs, labels=model.labels)\nplt.show()\n```\n\nNote that this repository only provides minimal code to infer the model.\nIf you wish to do additional training, [refer to the original repo](https://github.com/Megvii-BaseDetection/YOLOX).\n\n3. Advanced post-processing\n\nAdditional post-processing might be required to use the model as part of a data extraction pipeline. \nWe provide examples in the notebook `Demo.ipynb`.\n\n\n\n## Model Version(s):\n\n* `nemotron-page-elements-v3`\n\n## Training and Evaluation Datasets:\n\n### Training Dataset\n\n**Data Modality**: ","type":"text"},{"text":"Image","type":"highlight"},{"text":"
\n**","type":"text"},{"text":"Image","type":"highlight"},{"text":" Training Data Size**: Less than a Million ","type":"text"},{"text":"Image","type":"highlight"},{"text":"s
\n**Data collection method by dataset**: Automated
\n**Labeling method by dataset**: Hybrid: Automated, Human
\n**Pretraining (by NVIDIA)**: 118,287 ","type":"text"},{"text":"image","type":"highlight"},{"text":"s of the [COCO train2017](https://cocodataset.org/#download) dataset
\n**Finetuning (by NVIDIA)**: 36,093 ","type":"text"},{"text":"image","type":"highlight"},{"text":"s from [Digital Corpora dataset](https://digitalcorpora.org/), with annotations from [Azure AI Document Intelligence](https://azure.microsoft.com/en-us/products/ai-services/ai-document-intelligence) and data annotation team
\n**Number of bounding boxes per class**: 35,328 tables, 44,178 titles, 11,313 charts and 6,500 infographics, 90,812 texts and 10,743 header/footers. The layout model of Document Intelligence was used with `2024-02-29-preview` API version.\n\n### Evaluation Dataset\n\nThe primary evaluation set is a cut of the Azure labels and digital corpora ","type":"text"},{"text":"image","type":"highlight"},{"text":"s. Number of bounding boxes per class: 1,985 tables, 2,922 titles, 498 charts, 572 infographics, 4,400 texts and 492 header/footers. Mean Average Precision (mAP) was used as an evaluation metric, which measures the model's ability to correctly identify and localize objects across different confidence thresholds.\n\n**Data collection method by dataset**: Hybrid: Automated, Human
\n**Labeling method by dataset**: Hybrid: Automated, Human
\n**Properties**: We evaluated with Azure labels from manually selected pages, as well as manual inspection on public PDFs and powerpoint slides.\n\n**Per-class Performance Metrics**:\n| Class | AP (%) | AR (%) |\n|:------------|:-------|:-------|\n| table | 44.643 | 62.242 |\n| chart | 54.191 | 77.557 |\n| title | 38.529 | 56.315 |\n| infographic | 66.863 | 69.306 |\n| text | 45.418 | 73.017 |\n| header_footer | 53.895 | 75.670 |\n\n\n\n\n## Ethical Considerations\n\nNVIDIA believes Trustworthy AI is a shared responsibility and we have established policies and practices to enable development for a wide array of AI applications. When downloaded or used in accordance with our terms of service, developers should work with their internal model team to ensure this model meets requirements for the relevant industry and use case and addresses unforeseen product misuse.\n\n\n## Bias\n\n| Field | Response |\n| ----- | ----- |\n| Participation considerations from adversely impacted groups [protected classes](https://www.senate.ca.gov/content/protected-classes) in model design and testing | None |\n| Measures taken to mitigate against unwanted bias | None |\n\n## Explainability\n\n| Field | Response |\n| ----- | ----- |\n| Intended Task/Domain: | Document Understanding |\n| Model Type: | YOLOX Object Detection for Charts, Tables, Infographics, Header/footers, Texts, and Titles |\n| Intended User: | Enterprise developers, data scientists, and other technical users who need to extract structural elements from documents. |\n| Output: | After post-processing, the output is three numpy array that contains the detections: `boxes [N x 4]` (format is normalized `(x_min, y_min, x_max, y_max)`), associated classes: `labels [N]` and confidence scores: `scores [N]`.|\n| Describe how the model works: | The model identifies objects in an ","type":"text"},{"text":"image","type":"highlight"},{"text":" by first dividing the ","type":"text"},{"text":"image","type":"highlight"},{"text":" into a grid. For each grid cell, it extracts visual features and simultaneously predicts which objects are present (for example, 'chart' or 'table') and where they are located in that cell, all in a single pass through the ","type":"text"},{"text":"image","type":"highlight"},{"text":". |\n| Name the adversely impacted groups this has been tested to deliver comparable outcomes regardless of: | Not Applicable |\n| Technical Limitations & Mitigation: | The model may not generalize to unknown document types/formats not commonly found on the web. Further fine-tuning might be required for such documents. |\n| Verified to have met prescribed NVIDIA quality standards: | Yes |\n| Performance Metrics: | Mean Average Precision, detectionr recall and visual inspection |\n| Potential Known Risks: | This model may not always detect all elements in a document. |\n| Licensing & Terms of Use: | Use of this model is governed by [NVIDIA Open Model License Agreement](https://www.nvidia.com/en-us/agreements/enterprise-software/nvidia-open-model-license/) and the use of the post-processing scripts are licensed under [Apache 2.0](https://www.apache.org/licenses/LICENSE-2.0.txt). |\n\n## Privacy\n\n| Field | Response |\n| ----- | ----- |\n| Generatable or reverse engineerable personal data? | No |\n| Personal data used to create this model? | No |\n| Was consent obtained for any personal data used? | Not Applicable |\n| How often is the dataset reviewed? | Before Release |\n| Is there provenance for all datasets used in training? | Yes |\n| Does data labeling (annotation, metadata) comply with privacy laws? | Yes |\n| Is data compliant with data subject requests for data correction or removal, if such a request was made? | No, not possible with externally-sourced data. |\n| Applicable Privacy Policy | https://www.nvidia.com/en-us/about-nvidia/privacy-policy/ |\n\n## Safety\n\n| Field | Response |\n| ----- | ----- |\n| Model Application Field(s): | Object Detection for Retrieval, focused on Enterprise |\n| Describe the life critical impact (if present). | Not Applicable |\n| Use Case Restrictions: | Abide by [NVIDIA Open Model License Agreement](https://www.nvidia.com/en-us/agreements/enterprise-software/nvidia-open-model-license/) and the use of the post-processing scripts are licensed under [Apache 2.0](https://www.apache.org/licenses/LICENSE-2.0.txt). |\n| Model and dataset restrictions: | The Principle of least privilege (PoLP) is applied limiting access for dataset generation and model development. Restrictions enforce dataset access during training, and dataset license constraints adhered to. |\n","type":"text"}],"tags":[{"text":"image","type":"highlight"},{"text":", detection, pdf, ingestion, yolox, object-detection, en, arxiv:2107.08430, license:other, region:us","type":"text"}],"name":[{"text":"nvidia/nemotron-page-elements-v3","type":"text"}],"fileName":[{"text":"README.md","type":"text"}]},"authorData":{"_id":"60262b67268c201cdc8b7d43","avatarUrl":"https://cdn-avatars.huggingface.co/v1/production/uploads/65df9200dc3292a8983e5017/Vs5FPVCH-VZBipV3qKTuy.png","fullname":"NVIDIA","name":"nvidia","type":"org","isHf":false,"isHfAdmin":false,"isMod":false,"plan":"plus","followerCount":54672,"isUserFollowing":false}},{"repoId":"68f2503ccf93514423ee20a3","repoOwnerId":"60262b67268c201cdc8b7d43","isPrivate":false,"type":"model","likes":2,"isReadmeFile":true,"readmeStartLine":16,"updatedAt":1773834398253,"repoName":"nemotron-graphic-elements-v1","repoOwner":"nvidia","tags":"image, detection, pdf, ingestion, yolox, object-detection, en, arxiv:2107.08430, arxiv:2305.04151, license:other, region:us","name":"nvidia/nemotron-graphic-elements-v1","fileName":"README.md","formatted":{"repoName":[{"text":"nemotron-graphic-elements-v1","type":"text"}],"repoOwner":[{"text":"nvidia","type":"text"}],"fileContent":[{"text":"# Nemotron Graphic Element v1\n\n## **Model Overview**\n\n\n*Preview of the model output on the example ","type":"text"},{"text":"image","type":"highlight"},{"text":".*\n\nThe input of this model is expected to be a chart ","type":"text"},{"text":"image","type":"highlight"},{"text":". You can use the [Nemotron Page Element v3](https://huggingface.co/nvidia/nemotron-page-elements-v3) to detect and crop such ","type":"text"},{"text":"image","type":"highlight"},{"text":"s.\n\n### **Description**\n\nThe **Nemotron Graphic Elements v1** model is a specialized object detection system designed to identify and extract key elements from charts and graphs. Based on YOLOX, an anchor-free version of YOLO (You Only Look Once), this model combines a simpler architecture with enhanced performance. While the underlying technology builds upon work from [Megvii Technology](https://github.com/Megvii-BaseDetection/YOLOX), we developed our own base model through complete retraining rather than using pre-trained weights.\n\nThe model excels at detecting and localizing various graphic elements within chart ","type":"text"},{"text":"image","type":"highlight"},{"text":"s, including titles, axis labels, legends, and data point annotations. This capability makes it particularly valuable for document understanding tasks and automated data extraction from visual content.\n\nThis model is ready for commercial/non-commercial use.\n\nWe are excited to announce the open sourcing of this commercial model. For users interested in deploying this model in production environments, it is also available via the model API in NVIDIA Inference Microservices (NIM) at [nemotron-graphic-elements-v1](https://build.nvidia.com/nvidia/nemoretriever-graphic-elements-v1).\n\n### License/Terms of use\n\nThe use of this model is governed by the [NVIDIA Open Model License Agreement](https://www.nvidia.com/en-us/agreements/enterprise-software/nvidia-open-model-license/) and the use of the post-processing scripts are licensed under [Apache 2.0](https://www.apache.org/licenses/LICENSE-2.0.txt).\n\n### Team\n\n- Theo Viel\n- Bo Liu\n- Darragh Hanley\n- Even Oldridge\n\nCorrespondence to Theo Viel (tviel@nvidia.com) and Bo Liu (boli@nvidia.com)\n\n### Deployment Geography\n\nGlobal\n\n### Use Case\n\nThe **Nemotron Graphic Elements v1** is designed for automating extraction of graphic elements of charts in enterprise documents. Key applications include:\n- Enterprise document extraction, embedding and indexing\n- Augmenting Retrieval Augmented Generation (RAG) workflows with multimodal retrieval\n- Data extraction from legacy documents and reports\n\n\n### Release Date\n\n10/23/2025 via https://huggingface.co/nvidia/nemotron-graphic-elements-v1\n\n### References\n\n- YOLOX paper: https://arxiv.org/abs/2107.08430\n- YOLOX repo: https://github.com/Megvii-BaseDetection/YOLOX\n- CACHED paper: https://arxiv.org/abs/2305.04151\n- CACHED repo : https://github.com/pengyu965/ChartDete\n- Technical blog: https://developer.nvidia.com/blog/approaches-to-pdf-data-extraction-for-information-retrieval/\n\n### Model Architecture\n\n**Architecture Type**: YOLOX
\n**Network Architecture**: DarkNet53 Backbone \\+ FPN Decoupled head (one 1x1 convolution \\+ 2 parallel 3x3 convolutions (one for the classification and one for the bounding box prediction). YOLOX is a single-stage object detector that improves on Yolo-v3.
\n**This model was developed based on the Yolo architecture**
\n**Number of model parameters**: 5.4e7
\n\n### Input\n\n**Input Type(s)**: ","type":"text"},{"text":"Image","type":"highlight"},{"text":"
\n**Input Format(s)**: Red, Green, Blue (RGB)
\n**Input Parameters**: Two-Dimensional (2D)
\n**Other Properties Related to Input**: ","type":"text"},{"text":"Image","type":"highlight"},{"text":" size resized to `(1024, 1024)`\n\n\n### Output\n\n**Output Type(s)**: Array
\n**Output Format**: A dictionary of dictionaries containing `np.ndarray` objects. The outer dictionary has entries for each sample (page), and the inner dictionary contains a list of dictionaries, each with a bounding box (`np.ndarray`), class label, and confidence score for that page.
\n**Output Parameters**: One-Dimensional (1D)
\n**Other Properties Related to Output**: The output contains bounding boxes, detection confidence scores, and object classes (chart title, x/y axis titles and labels, legend title and labels, marker labels, value labels and other texts). The thresholds used for non-maximum suppression are `conf_thresh=0.01` and `iou_thresh=0.25`.
\n\n**Output Classes**:
\n * Chart title\n * Title or caption associated to the chart\n * x-axis title\n * Title associated to the x axis\n * y-axis title\n * Title associated to the y axis\n * x-axis label(s)\n * Labels associated to the x axis\n * y-axis label(s)\n * Labels associated to the y axis\n * Legend title\n * Title of the legend\n * Legend label(s)\n * Labels associated to the legend\n * Marker label(s)\n * Labels associated to markers\n * Value label(s)\n * Labels associated to values\n * Other\n * Miscellaneous other text components\n\nOur AI models are designed and/or optimized to run on NVIDIA GPU-accelerated systems. By leveraging NVIDIA’s hardware (e.g. GPU cores) and software frameworks (e.g., CUDA libraries), the model achieves faster training and inference times compared to CPU-only solutions.\n\n### Usage\n\nThe model requires torch, and the custom code available in this repository.\n\n1. Clone the repository\n\n- Make sure git-lfs is installed (https://git-lfs.com)\n```\ngit lfs install\n```\n- Using https\n```\ngit clone https://huggingface.co/nvidia/nemotron-graphic-elements-v1\n```\n- Or using ssh\n```\ngit clone git@hf.co:nvidia/nemotron-graphic-elements-v1\n```\nOptional:\nThis can be installed as a package using pip\n```\ncd nemotron-graphic-elements-v3\npip install -e .\n```\n2. Run the model using the following code:\n\n```\nimport torch\nimport numpy as np\nimport matplotlib.pyplot as plt\nfrom PIL import ","type":"text"},{"text":"Image","type":"highlight"},{"text":"\n\nfrom nemotron_graphic_elements_v1.model import define_model\nfrom nemotron_graphic_elements_v1.utils import plot_sample, postprocess_preds_graphic_element, reformat_for_plotting\n\n# Load ","type":"text"},{"text":"image","type":"highlight"},{"text":"\npath = \"./example.png\"\nimg = ","type":"text"},{"text":"Image","type":"highlight"},{"text":".open(path).convert(\"RGB\")\nimg = np.array(img)\n\n# Load model\nmodel = define_model(\"graphic_element_v1\")\n\n# Inference\nwith torch.inference_mode():\n x = model.preprocess(img)\n preds = model(x, img.shape)[0]\n\nprint(preds)\n\n# Post-processing\nboxes, labels, scores = postprocess_preds_graphic_element(preds, model.threshold, model.labels)\n\n# Plot\nboxes_plot, confs = reformat_for_plotting(boxes, labels, scores, img.shape, model.num_classes)\n\nplt.figure(figsize=(15, 10))\nplot_sample(img, boxes_plot, confs, labels=model.labels)\nplt.show()\n```\n\nNote that this repository only provides minimal code to infer the model.\nIf you wish to do additional training, [refer to the original repo](https://github.com/Megvii-BaseDetection/YOLOX).\n\n3. Advanced post-processing\n\nAdditional post-processing might be required to use the model as part of a data extraction pipeline. \nWe provide examples in the notebook `Demo.ipynb`.\n\n\n\n## Model Version(s):\n\n* `nemotron-graphic-elements-v1`\n\n## Training and Evaluation Datasets:\n\n### Training Dataset\n\n**Data Modality**: ","type":"text"},{"text":"Image","type":"highlight"},{"text":"
\n**","type":"text"},{"text":"Image","type":"highlight"},{"text":" Training Data Size**: Less than a Million ","type":"text"},{"text":"Image","type":"highlight"},{"text":"s
\n**Data collection method by dataset**: Automated
\n**Labeling method by dataset**: Hybrid: Automated, Human
\n**Pretraining (by NVIDIA)**: 118,287 ","type":"text"},{"text":"image","type":"highlight"},{"text":"s of the [COCO train2017](https://cocodataset.org/#download) dataset
\n**Finetuning (by NVIDIA)**: 5,614 ","type":"text"},{"text":"image","type":"highlight"},{"text":"s from the [PubMed Central (PMC) Chart Dataset](https://chartinfo.github.io/index_2022.html). 9,091 ","type":"text"},{"text":"image","type":"highlight"},{"text":"s from the [DeepRule Dataset](https://github.com/soap117/DeepRule) with annotations obtained using the [CACHED model](https://github.com/pengyu965/ChartDete)
\n**Number of bounding boxes per class**:\n| **Label** | **","type":"text"},{"text":"Image","type":"highlight"},{"text":"s** | **Boxes** |\n| :--------------- | ---------: | ----------: |\n| **chart_title** | 9,487 | 18,754 |\n| **x_title** | 5,995 | 9,152 |\n| **y_title** | 8,487 | 12,893 |\n| **xlabel** | 13,227 | 217,820 |\n| **ylabel** | 12,983 | 172,431 |\n| **legend_title** | 168 | 209 |\n| **legend_label** | 9,812 | 59,044 |\n| **mark_label** | 660 | 2,887 |\n| **value_label** | 3,573 | 65,847 |\n| **other** | 3,717 | 29,565 |\n| **Total** | **14,143** | **588,602** |\n\n\n### Evaluation Dataset\n\nResults were evaluated using the **PMC Chart dataset**. The **Mean Average Precision (mAP)** was used as the evaluation metric to measure the model's ability to correctly identify and localize objects across different confidence thresholds.\n\n**Number of bounding boxes and ","type":"text"},{"text":"image","type":"highlight"},{"text":"s per class:**\n| **Label** | **","type":"text"},{"text":"Image","type":"highlight"},{"text":"s** | **Boxes** |\n| :--------------- | ---------: | ---------: |\n| **chart_title** | 38 | 38 |\n| **x_title** | 404 | 437 |\n| **y_title** | 502 | 505 |\n| **xlabel** | 553 | 4,091 |\n| **ylabel** | 534 | 3,944 |\n| **legend_title** | 17 | 19 |\n| **legend_label** | 318 | 1,077 |\n| **mark_label** | 42 | 219 |\n| **value_label** | 52 | 726 |\n| **other** | 113 | 464 |\n| **Total** | **560** | **11,520** |\n\n\n**Data collection method by dataset**: Hybrid: Automated, Human
\n**Labeling method by dataset**: Hybrid: Automated, Human
\n**Properties**: The validation dataset is the same as the **PMC Chart dataset**.\n\n**Per-class Performance Metrics**:\n| Class | AP (%) | AR (%) |\n| :----------- | :----- | :----- |\n| chart_title | 82.38 | 93.16 |\n| x_title | 88.77 | 92.31 |\n| y_title | 89.48 | 92.32 |\n| xlabel | 85.04 | 88.93 |\n| ylabel | 86.22 | 89.40 |\n| other | 55.14 | 79.48 |\n| legend_label | 84.09 | 88.07 |\n| legend_title | 60.61 | 68.42 |\n| mark_label | 49.31 | 73.61 |\n| value_label | 62.66 | 68.32 |\n\n\n\n## Ethical Considerations\n\nNVIDIA believes Trustworthy AI is a shared responsibility and we have established policies and practices to enable development for a wide array of AI applications. When downloaded or used in accordance with our terms of service, developers should work with their internal model team to ensure this model meets requirements for the relevant industry and use case and addresses unforeseen product misuse.
\nFor more detailed information on ethical considerations for this model, please see the Explainability, Bias, Safety & Security, and Privacy sections below.
\nPlease report security vulnerabilities or NVIDIA AI Concerns [here](https://app.intigriti.com/programs/nvidia/nvidiavdp/detail).\n\n## Bias\n\n| Field | Response |\n| ----- | ----- |\n| Participation considerations from adversely impacted groups [protected classes](https://www.senate.ca.gov/content/protected-classes) in model design and testing | None |\n| Measures taken to mitigate against unwanted bias | None |\n\n## Explainability\n\n| Field | Response |\n| ----- | ----- |\n| Intended Application & Domain: | Object Detection |\n| Model Type: | YOLOX-architecture for detection of graphic elements within ","type":"text"},{"text":"image","type":"highlight"},{"text":"s of charts. |\n| Intended User: | Enterprise developers, data scientists, and other technical users who need to extract textual elements from charts and graphs. |\n| Output: | After post-processing, the output is three numpy array that contains the detections: `boxes [N x 4]` (format is normalized `(x_min, y_min, x_max, y_max)`), associated classes: `labels [N]` and confidence scores: `scores [N]`.|\n| Describe how the model works: | Finds and identifies objects in ","type":"text"},{"text":"image","type":"highlight"},{"text":"s by first dividing the ","type":"text"},{"text":"image","type":"highlight"},{"text":" into a grid. For each section of the grid, the model uses a series of neural networks to extract visual features and simultaneously predict what objects are present (in this case \"chart title\" or \"axis label\" etc.) and exactly where they are located in that section, all in a single pass through the ","type":"text"},{"text":"image","type":"highlight"},{"text":". |\n| Name the adversely impacted groups this has been tested to deliver comparable outcomes regardless of: | Not Applicable |\n| Technical Limitations & Mitigation: | The model may not generalize to unknown chart types/formats. Further fine-tuning might be required for such ","type":"text"},{"text":"image","type":"highlight"},{"text":"s. |\n| Verified to have met prescribed NVIDIA quality standards: | Yes |\n| Performance Metrics: | Mean Average Precision, detectionr recall and visual inspection |\n| Potential Known Risks: | This model may not always detect all elements in a document. |\n| Licensing & Terms of Use: | Use of this model is governed by [NVIDIA Open Model License Agreement](https://www.nvidia.com/en-us/agreements/enterprise-software/nvidia-open-model-license/) and the use of the post-processing scripts are licensed under [Apache 2.0](https://www.apache.org/licenses/LICENSE-2.0.txt). |\n\n\n## Privacy\n\n| Field | Response |\n| ----- | ----- |\n| Generatable or reverse engineerable personal data? | No |\n| Personal data used to create this model? | No |\n| Was consent obtained for any personal data used? | Not Applicable |\n| How often is the dataset reviewed? | Before Release |\n| Is there provenance for all datasets used in training? | Yes |\n| Does data labeling (annotation, metadata) comply with privacy laws? | Yes |\n| Is data compliant with data subject requests for data correction or removal, if such a request was made? | No, not possible with externally-sourced data. |\n| Applicable Privacy Policy | https://www.nvidia.com/en-us/about-nvidia/privacy-policy/ |\n\n## Safety\n\n| Field | Response |\n| ----- | ----- |\n| Model Application Field(s): | Object Detection for Retrieval, focused on Enterprise |\n| Describe the life critical impact (if present). | Not Applicable |\n| Use Case Restrictions: | Abide by [NVIDIA Open Model License Agreement](https://www.nvidia.com/en-us/agreements/enterprise-software/nvidia-open-model-license/) and the use of the post-processing scripts are licensed under [Apache 2.0](https://www.apache.org/licenses/LICENSE-2.0.txt). |\n| Model and dataset restrictions: | The Principle of least privilege (PoLP) is applied limiting access for dataset generation and model development. Restrictions enforce dataset access during training, and dataset license constraints adhered to. |\n","type":"text"}],"tags":[{"text":"image","type":"highlight"},{"text":", detection, pdf, ingestion, yolox, object-detection, en, arxiv:2107.08430, arxiv:2305.04151, license:other, region:us","type":"text"}],"name":[{"text":"nvidia/nemotron-graphic-elements-v1","type":"text"}],"fileName":[{"text":"README.md","type":"text"}]},"authorData":{"_id":"60262b67268c201cdc8b7d43","avatarUrl":"https://cdn-avatars.huggingface.co/v1/production/uploads/65df9200dc3292a8983e5017/Vs5FPVCH-VZBipV3qKTuy.png","fullname":"NVIDIA","name":"nvidia","type":"org","isHf":false,"isHfAdmin":false,"isMod":false,"plan":"plus","followerCount":54672,"isUserFollowing":false}},{"repoId":"68f250582d2124fceb9cd3b2","repoOwnerId":"60262b67268c201cdc8b7d43","isPrivate":false,"type":"model","likes":2,"isReadmeFile":true,"readmeStartLine":16,"updatedAt":1773834398254,"repoName":"nemotron-table-structure-v1","repoOwner":"nvidia","tags":"image, detection, pdf, ingestion, yolox, object-detection, en, arxiv:2107.08430, license:other, region:us","name":"nvidia/nemotron-table-structure-v1","fileName":"README.md","formatted":{"repoName":[{"text":"nemotron-table-structure-v1","type":"text"}],"repoOwner":[{"text":"nvidia","type":"text"}],"fileContent":[{"text":"# Nemotron Table Structure v1\n\n## **Model Overview**\n\n\n\n*Preview of the model output on the example ","type":"text"},{"text":"image","type":"highlight"},{"text":".*\n\nThe input of this model is expected to be a table ","type":"text"},{"text":"image","type":"highlight"},{"text":". You can use the [Nemotron Page Element v3](https://huggingface.co/nvidia/nemotron-page-elements-v3) to detect and crop such ","type":"text"},{"text":"image","type":"highlight"},{"text":"s.\n\n### Description\n\nThe **Nemotron Table Structure v1** model is a specialized object detection model designed to identify and extract the structure of tables in ","type":"text"},{"text":"image","type":"highlight"},{"text":"s. Based on YOLOX, an anchor-free version of YOLO (You Only Look Once), this model combines a simpler architecture with enhanced performance. While the underlying technology builds upon work from [Megvii Technology](https://github.com/Megvii-BaseDetection/YOLOX), we developed our own base model through complete retraining rather than using pre-trained weights.\n\nThe model excels at detecting and localizing the fundamental structural elements within tables. Through careful fine-tuning, it can accurately identify and delineate three key components within tables:\n\n1. Individual cells (including merged cells)\n2. Rows\n3. Columns\n\nThis specialized focus on table structure enables precise decomposition of complex tables into their constituent parts, forming the foundation for downstream retrieval tasks. This model helps convert tables into the markdown format which can improve retrieval accuracy.\n\nThis model is ready for commercial/non-commercial use.\n\nWe are excited to announce the open sourcing of this commercial model. For users interested in deploying this model in production environments, it is also available via the model API in NVIDIA Inference Microservices (NIM) at [nemotron-table-structure-v1](https://build.nvidia.com/nvidia/nemoretriever-table-structure-v1).\n\n### License/Terms of use\n\nThe use of this model is governed by the [NVIDIA Open Model License Agreement](https://www.nvidia.com/en-us/agreements/enterprise-software/nvidia-open-model-license/) and the use of the post-processing scripts are licensed under [Apache 2.0](https://www.apache.org/licenses/LICENSE-2.0.txt).\n\n### Team\n\n- Theo Viel\n- Bo Liu\n- Darragh Hanley\n- Even Oldridge\n\nCorrespondence to Theo Viel (tviel@nvidia.com) and Bo Liu (boli@nvidia.com)\n\n### Deployment Geography\n\nGlobal\n\n### Use Case\n\nThe **Nemotron Table Structure v1** model specializes in analyzing ","type":"text"},{"text":"image","type":"highlight"},{"text":"s containing tables by:\n- Detecting and extracting table structure elements (rows, columns, and cells)\n- Providing precise location information for each detected element\n- Supporting downstream tasks like table analysis and data extraction\n\nThe model is designed to work in conjunction with OCR (Optical Character Recognition) systems to:\n1. Identify the structural layout of tables\n2. Preserve the relationships between table elements\n3. Enable accurate extraction of tabular data from ","type":"text"},{"text":"image","type":"highlight"},{"text":"s\n\nIdeal for:\n- Document processing systems\n- Automated data extraction pipelines\n- Digital content management solutions\n- Business intelligence applications\n\n### Release Date\n\n10/23/2025 via https://huggingface.co/nvidia/nemotron-table-structure-v1\n\n### References\n\n- YOLOX paper: https://arxiv.org/abs/2107.08430\n- YOLOX repo: https://github.com/Megvii-BaseDetection/YOLOX\n- Technical blog: https://developer.nvidia.com/blog/approaches-to-pdf-data-extraction-for-information-retrieval/\n\n### Model Architecture\n\n**Architecture Type**: YOLOX
\n**Network Architecture**: DarkNet53 Backbone \\+ FPN Decoupled head (one 1x1 convolution \\+ 2 parallel 3x3 convolutions (one for the classification and one for the bounding box prediction). YOLOX is a single-stage object detector that improves on Yolo-v3.
\n**This model was developed based on the Yolo architecture**
\n**Number of model parameters**: 5.4e7
\n\n### Input\n\n**Input Type(s)**: ","type":"text"},{"text":"Image","type":"highlight"},{"text":"
\n**Input Format(s)**: Red, Green, Blue (RGB)
\n**Input Parameters**: Two-Dimensional (2D)
\n**Other Properties Related to Input**: ","type":"text"},{"text":"Image","type":"highlight"},{"text":" size resized to `(1024, 1024)`\n\n### Output\n\n**Output Type(s)**: Array
\n**Output Format**: A dictionary of dictionaries containing `np.ndarray` objects. The outer dictionary has entries for each sample (page), and the inner dictionary contains a list of dictionaries, each with a bounding box (`np.ndarray`), class label, and confidence score for that page.
\n**Output Parameters**: One-Dimensional (1D)
\n**Other Properties Related to Output**: The output contains bounding boxes, detection confidence scores, and object classes (cell, row, column). The thresholds used for non-maximum suppression are `conf_thresh = 0.01` and `iou_thresh = 0.25`\n**Output Classes**:
\n * Cell\n * Table cell\n * Row\n * Table row\n * Column\n * Table column\n\nOur AI models are designed and/or optimized to run on NVIDIA GPU-accelerated systems. By leveraging NVIDIA’s hardware (e.g. GPU cores) and software frameworks (e.g., CUDA libraries), the model achieves faster training and inference times compared to CPU-only solutions.\n\n\n### Usage\n\nThe model requires torch, and the custom code available in this repository.\n\n1. Clone the repository\n\n- Make sure git-lfs is installed (https://git-lfs.com)\n```\ngit lfs install\n```\n- Using https\n```\ngit clone https://huggingface.co/nvidia/nemotron-table-structure-v1\n```\n- Or using ssh\n```\ngit clone git@hf.co:nvidia/nemotron-table-structure-v1\n```\nOptional:\nThis can be installed as a package using pip\n```\ncd nemotron-table-structure-v1\npip install -e .\n```\n2. Run the model using the following code:\n\n```\nimport torch\nimport numpy as np\nimport matplotlib.pyplot as plt\nfrom PIL import ","type":"text"},{"text":"Image","type":"highlight"},{"text":"\n\nfrom nemotron_table_structure_v1 import (\n define_model,\n plot_sample,\n postprocess_preds_table_structure,\n reformat_for_plotting,\n)\n\n# Load ","type":"text"},{"text":"image","type":"highlight"},{"text":"\npath = \"./example.png\"\nimg = ","type":"text"},{"text":"Image","type":"highlight"},{"text":".open(path).convert(\"RGB\")\nimg = np.array(img)\n\n# Load model\nmodel = define_model(\"table_structure_v1\")\n\n# Inference\nwith torch.inference_mode():\n x = model.preprocess(img)\n preds = model(x, img.shape)[0]\n\n# Post-processing\nboxes, labels, scores = postprocess_preds_table_structure(preds, model.threshold, model.labels)\n\n# Plot\nboxes_plot, confs = reformat_for_plotting(boxes, labels, scores, img.shape, model.num_classes)\n\nplt.figure(figsize=(30, 15))\nfor i in range(1, 4):\n boxes_plot_c = [b if j == i else [] for j, b in enumerate(boxes_plot)]\n confs_c = [c if j == i else [] for j, c in enumerate(confs)]\n\n plt.subplot(1, 3, i)\n plt.title(model.labels[i])\n plot_sample(img, boxes_plot_c, confs_c, labels=model.labels, show_text=False)\nplt.show()\n```\n\nNote that this repository only provides minimal code to infer the model.\nIf you wish to do additional training, [refer to the original repo](https://github.com/Megvii-BaseDetection/YOLOX).\n\n3. Advanced post-processing\n\nAdditional post-processing might be required to use the model as part of a data extraction pipeline. \nWe show how to use the model as part of a table to text pipeline alongside with the [Nemotron OCR](https://huggingface.co/nvidia/nemotron-ocr-v1) in the notebook `Demo.ipynb`.\n\n**Disclaimer:**\nWe are aware of some issues with the model, and will provide a v2 with improved performance in the future which addresses the following issues:\n- The model appears to be less confident in detecting cells in the bottom of the table, which sometimes results in missed cells.\n- Add an extra class for table titles\n- Add support for non full-page tables\n\n\n\n## Model Version(s):\n\n* `nemotron-table-structure-v1`\n\n## Training and Evaluation Datasets:\n\n### Training Dataset\n\n**Data Modality**: ","type":"text"},{"text":"Image","type":"highlight"},{"text":"
\n**","type":"text"},{"text":"Image","type":"highlight"},{"text":" Training Data Size**: Less than a Million ","type":"text"},{"text":"Image","type":"highlight"},{"text":"s
\n**Data collection method by dataset**: Automated
\n**Labeling method by dataset**: Automated
\n**Pretraining (by NVIDIA)**: 118,287 ","type":"text"},{"text":"image","type":"highlight"},{"text":"s of the [COCO train2017](https://cocodataset.org/#download) dataset
\n**Finetuning (by NVIDIA)**: 23,977 ","type":"text"},{"text":"image","type":"highlight"},{"text":"s from [Digital Corpora dataset](https://digitalcorpora.org/), with annotations from [Azure AI Document Intelligence](https://azure.microsoft.com/en-us/products/ai-services/ai-document-intelligence).
\n**Number of bounding boxes per class:** 1,828,978 cells, 134,089 columns and 316,901 rows. The layout model of Document Intelligence was used with `2024-02-29-preview` API version.\n\n### Evaluation Results\n\nThe primary evaluation set is a cut of the Azure labels and digital corpora ","type":"text"},{"text":"image","type":"highlight"},{"text":"s. Number of bounding boxes per class: 200,840 cells, 13,670 columns and 34,575 rows. Mean Average Precision (mAP) was used as an evaluation metric, which measures the model's ability to correctly identify and localize objects across different confidence thresholds.\n\n**Data collection method by dataset**: Hybrid: Automated, Human
\n**Labeling method by dataset**: Hybrid: Automated, Human
\n**Properties**: We evaluated with Azure labels from manually selected pages, as well as manual inspection on public PDFs and powerpoint slides.\n\n**Per-class Performance Metrics**:\n| Class | AP (%) | AR (%) |\n|:-------|:-------|:-------|\n| cell | 58.365 | 60.647 |\n| row | 76.992 | 81.115 |\n| column | 85.293 | 87.434 |\n\n\n\n## Ethical Considerations\n\nNVIDIA believes Trustworthy AI is a shared responsibility and we have established policies and practices to enable development for a wide array of AI applications. When downloaded or used in accordance with our terms of service, developers should work with their internal model team to ensure this model meets requirements for the relevant industry and use case and addresses unforeseen product misuse.
\nFor more detailed information on ethical considerations for this model, please see the Explainability, Bias, Safety & Security, and Privacy sections below.
\nPlease report security vulnerabilities or NVIDIA AI Concerns [here](https://app.intigriti.com/programs/nvidia/nvidiavdp/detail).\n\n## Bias\n\n| Field | Response |\n| ----- | ----- |\n| Participation considerations from adversely impacted groups [protected classes](https://www.senate.ca.gov/content/protected-classes) in model design and testing | None |\n| Measures taken to mitigate against unwanted bias | None |\n\n## Explainability\n\n| Field | Response |\n| ----- | ----- |\n| Intended Application & Domain: | Object Detection |\n| Model Type: | YOLOX-architecture for detection of table structure within ","type":"text"},{"text":"image","type":"highlight"},{"text":"s of tables. |\n| Intended User: | Enterprise developers, data scientists, and other technical users who need to extract table structure from ","type":"text"},{"text":"image","type":"highlight"},{"text":"s. |\n| Output: | After post-processing, the output is three numpy array that contains the detections: `boxes [N x 4]` (format is normalized `(x_min, y_min, x_max, y_max)`), associated classes: `labels [N]` and confidence scores: `scores [N]`.|\n| Describe how the model works: | Finds and identifies objects in ","type":"text"},{"text":"image","type":"highlight"},{"text":"s by first dividing the ","type":"text"},{"text":"image","type":"highlight"},{"text":" into a grid. For each section of the grid, the model uses a series of neural networks to extract visual features and simultaneously predict what objects are present (in this case \"cell\", \"row\", or \"column\") and exactly where they are located in that section, all in a single pass through the ","type":"text"},{"text":"image","type":"highlight"},{"text":". |\n| Name the adversely impacted groups this has been tested to deliver comparable outcomes regardless of: | Not Applicable |\n| Technical Limitations & Mitigation: | The model may not generalize to unknown table formats. Further fine-tuning might be required for such documents. Furthermore, it is not robust to rotated tables. |\n| Verified to have met prescribed NVIDIA quality standards: | Yes |\n| Performance Metrics: | Mean Average Precision, detectionr recall and visual inspection |\n| Potential Known Risks: | This model may not always detect all elements in a document. |\n| Licensing & Terms of Use: | Use of this model is governed by [NVIDIA Open Model License Agreement](https://www.nvidia.com/en-us/agreements/enterprise-software/nvidia-open-model-license/) and the use of the post-processing scripts are licensed under [Apache 2.0](https://www.apache.org/licenses/LICENSE-2.0.txt). |\n\n## Privacy\n\n| Field | Response |\n| ----- | ----- |\n| Generatable or reverse engineerable personal data? | No |\n| Personal data used to create this model? | No |\n| Was consent obtained for any personal data used? | Not Applicable |\n| How often is the dataset reviewed? | Before Release |\n| Is there provenance for all datasets used in training? | Yes |\n| Does data labeling (annotation, metadata) comply with privacy laws? | Yes |\n| Is data compliant with data subject requests for data correction or removal, if such a request was made? | No, not possible with externally-sourced data. |\n| Applicable Privacy Policy | https://www.nvidia.com/en-us/about-nvidia/privacy-policy/ |\n\n## Safety\n\n| Field | Response |\n| ----- | ----- |\n| Model Application Field(s): | Object Detection for Retrieval, focused on Enterprise |\n| Describe the life critical impact (if present). | Not Applicable |\n| Use Case Restrictions: | Abide by [NVIDIA Open Model License Agreement](https://www.nvidia.com/en-us/agreements/enterprise-software/nvidia-open-model-license/) and the use of the post-processing scripts are licensed under [Apache 2.0](https://www.apache.org/licenses/LICENSE-2.0.txt). |\n| Model and dataset restrictions: | The Principle of least privilege (PoLP) is applied limiting access for dataset generation and model development. Restrictions enforce dataset access during training, and dataset license constraints adhered to. |\n","type":"text"}],"tags":[{"text":"image","type":"highlight"},{"text":", detection, pdf, ingestion, yolox, object-detection, en, arxiv:2107.08430, license:other, region:us","type":"text"}],"name":[{"text":"nvidia/nemotron-table-structure-v1","type":"text"}],"fileName":[{"text":"README.md","type":"text"}]},"authorData":{"_id":"60262b67268c201cdc8b7d43","avatarUrl":"https://cdn-avatars.huggingface.co/v1/production/uploads/65df9200dc3292a8983e5017/Vs5FPVCH-VZBipV3qKTuy.png","fullname":"NVIDIA","name":"nvidia","type":"org","isHf":false,"isHfAdmin":false,"isMod":false,"plan":"plus","followerCount":54672,"isUserFollowing":false}},{"repoId":"6489344ecbda0d1cdb976702","repoOwnerId":"63bf7ba8da08ed0544ff20e9","isPrivate":false,"type":"model","likes":1,"isReadmeFile":true,"readmeStartLine":8,"updatedAt":1770222784013,"repoName":"recognize_anything_model","repoOwner":"xinyu1205","tags":"image tagging, image captioning, image-to-text, en, arxiv:2306.03514, arxiv:2303.05657, license:mit, region:us","name":"xinyu1205/recognize_anything_model","fileName":"README.md","formatted":{"repoName":[{"text":"recognize_anything_model","type":"text"}],"repoOwner":[{"text":"xinyu1205","type":"text"}],"fileContent":[{"text":"\n# Recognize Anything & Tag2Text\n\nModel card for Recognize Anything: A Strong ","type":"text"},{"text":"Image","type":"highlight"},{"text":" Tagging Model and Tag2Text: Guiding Vision-Language Model via ","type":"text"},{"text":"Image","type":"highlight"},{"text":" Tagging.\n\n**Recognition and localization are two foundation computer vision tasks.**\n- **The Segment Anything Model (SAM)** excels in **localization capabilities**, while it falls short when it comes to **recognition tasks**.\n- **The Recognize Anything Model (RAM) and Tag2Text** exhibits **exceptional recognition abilities**, in terms of **both accuracy and scope**.\n- \n|  |\n|:--:|\n| Pull figure from recognize-anything official repo | ","type":"text"},{"text":"Image","type":"highlight"},{"text":" source: https://recognize-anything.github.io/ |\n\n## TL;DR\n\nAuthors from the [paper](https://arxiv.org/abs/2306.03514) write in the abstract:\n\n*We present the Recognize Anything Model~(RAM): a strong foundation model for ","type":"text"},{"text":"image","type":"highlight"},{"text":" tagging. RAM makes a substantial step for large models in computer vision, demonstrating the zero-shot ability to recognize any common category with high accuracy. By leveraging large-scale ","type":"text"},{"text":"image","type":"highlight"},{"text":"-text pairs for training instead of manual annotations, RAM introduces a new paradigm for ","type":"text"},{"text":"image","type":"highlight"},{"text":" tagging. We evaluate the tagging capability of RAM on numerous benchmarks and observe an impressive zero-shot performance, which significantly outperforms CLIP and BLIP. Remarkably, RAM even surpasses fully supervised models and exhibits a competitive performance compared with the Google tagging API.*\n\n\n## BibTex and citation info\n\n```\n@article{zhang2023recognize,\n title={Recognize Anything: A Strong ","type":"text"},{"text":"Image","type":"highlight"},{"text":" Tagging Model},\n author={Zhang, Youcai and Huang, Xinyu and Ma, Jinyu and Li, Zhaoyang and Luo, Zhaochuan and Xie, Yanchun and Qin, Yuzhuo and Luo, Tong and Li, Yaqian and Liu, Shilong and others},\n journal={arXiv preprint arXiv:2306.03514},\n year={2023}\n}\n\n@article{huang2023tag2text,\n\n title={Tag2Text: Guiding Vision-Language Model via ","type":"text"},{"text":"Image","type":"highlight"},{"text":" Tagging},\n author={Huang, Xinyu and Zhang, Youcai and Ma, Jinyu and Tian, Weiwei and Feng, Rui and Zhang, Yuejie and Li, Yaqian and Guo, Yandong and Zhang, Lei},\n journal={arXiv preprint arXiv:2303.05657},\n year={2023}\n}\n```\n","type":"text"}],"tags":[{"text":"image","type":"highlight"},{"text":" tagging, ","type":"text"},{"text":"image","type":"highlight"},{"text":" captioning, ","type":"text"},{"text":"image","type":"highlight"},{"text":"-to-text, en, arxiv:2306.03514, arxiv:2303.05657, license:mit, region:us","type":"text"}],"name":[{"text":"xinyu1205/recognize_anything_model","type":"text"}],"fileName":[{"text":"README.md","type":"text"}]},"authorData":{"_id":"63bf7ba8da08ed0544ff20e9","avatarUrl":"https://cdn-avatars.huggingface.co/v1/production/uploads/1673493776367-63bf7ba8da08ed0544ff20e9.jpeg","fullname":"Xinyu Huang","name":"xinyu1205","type":"user","isPro":false,"isHf":false,"isHfAdmin":false,"isMod":false,"followerCount":51,"isUserFollowing":false}},{"repoId":"65a817e5b33c64c60e79c62d","repoOwnerId":"652be5c0c59e682042eda635","isPrivate":false,"type":"model","likes":1,"isReadmeFile":true,"readmeStartLine":10,"updatedAt":1765223497943,"repoName":"Kvi-Upscale-V1","repoOwner":"kviai","tags":"diffusers, Image Upscaling, Img2Img, image-to-image, en, license:cc-by-4.0, region:us","name":"kviai/Kvi-Upscale-V1","fileName":"README.md","formatted":{"repoName":[{"text":"Kvi-Upscale-V1","type":"text"}],"repoOwner":[{"text":"kviai","type":"text"}],"fileContent":[{"text":"### ","type":"text"},{"text":"Image","type":"highlight"},{"text":" Upscaling Model\n\nThis repository contains the PyTorch model for upscaling ","type":"text"},{"text":"image","type":"highlight"},{"text":"s. The model has been trained to upscale low-resolution ","type":"text"},{"text":"image","type":"highlight"},{"text":"s to higher resolution using convolutional neural networks.\n\n## Model Details\n- Model Name: Kvi-Upscale\n- Author: KviAI\n- License: Creative Commons Attribution 4.0\n\n## Instructions\nTo use this model for upscaling, please follow the instructions in the accompanying Python script.","type":"text"}],"tags":[{"text":"diffusers, ","type":"text"},{"text":"Image","type":"highlight"},{"text":" Upscaling, Img2Img, ","type":"text"},{"text":"image","type":"highlight"},{"text":"-to-image, en, license:cc-by-4.0, region:us","type":"text"}],"name":[{"text":"kviai/Kvi-Upscale-V1","type":"text"}],"fileName":[{"text":"README.md","type":"text"}]},"authorData":{"_id":"652be5c0c59e682042eda635","avatarUrl":"https://cdn-avatars.huggingface.co/v1/production/uploads/6515cfef26224cf8b1eb8e2f/BXyrLqZKKgnCEmkYcIqe-.png","fullname":"KVIAI","name":"kviai","type":"org","isHf":false,"isHfAdmin":false,"isMod":false,"followerCount":13,"isUserFollowing":false}},{"repoId":"68b9a21a73a45ee60ac70a86","repoOwnerId":"64e6956097b2582a5dbacc5a","isPrivate":false,"type":"model","likes":1,"isReadmeFile":true,"readmeStartLine":15,"updatedAt":1765226329498,"repoName":"laptophunterbiden_v1-qwen_image","repoOwner":"huwhitememes","tags":"image, lora, qwen, hunter-biden, generative-image, huwhitememes, Meme King Studio, Green Frog Labs, NSFW, text-to-image, base_model:Qwen/Qwen-Image, base_model:adapter:Qwen/Qwen-Image, license:apache-2.0, region:us","name":"huwhitememes/laptophunterbiden_v1-qwen_image","fileName":"README.md","formatted":{"repoName":[{"text":"laptophunterbiden_v1-qwen_image","type":"text"}],"repoOwner":[{"text":"huwhitememes","type":"text"}],"fileContent":[{"text":"\n# Laptop Hunter Biden LoRA for Qwen ","type":"text"},{"text":"Image","type":"highlight"},{"text":" V1\n\nThis is a custom-trained **LoRA (Low-Rank Adapter)** for **Qwen ","type":"text"},{"text":"Image","type":"highlight"},{"text":"**, fine-tuned on 85+ upscaled and varied ","type":"text"},{"text":"image","type":"highlight"},{"text":"s sourced from the infamous Hunter Biden iCloud laptop archive. Designed for **Qwen-based ","type":"text"},{"text":"image","type":"highlight"},{"text":" generation**, this LoRA supports photorealistic and meme-style compositions for digital propaganda, viral satire, and social media chaos. Trained by [@huwhitememes](https://x.com/huwhitememes) using the [WaveSpeedAI LoRA Trainer](https://wavespeed.ai/models/wavespeed-ai/qwen-image-lora-trainer) pipeline.\n\n## 🎯 Use Cases\n- Shitposts and meme edits \n- NSFW digital satire \n- Political propaganda art \n- Cursed cultural archetypes \n\n## 🔧 Training Details\n- **Base Model**: Qwen/Qwen-Image \n- **Steps**: ~1000 \n- **LoRA Rank**: 16 \n- **Learning Rate**: 0.00004 \n- **GPU**: Nvidia H100 (WaveSpeedAI) \n- **","type":"text"},{"text":"Image","type":"highlight"},{"text":" Count**: 85 (curated, upscaled, real-world lighting) \n- **Trigger Word**: `Hunt3r Bid3n` (recommended at start of prompt)\n\n---\n\n## 🧠 Creator\n\nCreated and uploaded by [@huwhitememes](https://x.com/huwhitememes) \nPart of the Meme King Studio / Green Frog Labs creative ecosystem.\n\n## ⚠️ Legal & Fair Use\n\nThis model was trained on **publicly circulated content** tied to a high-profile public figure. \nIt is provided under Fair Use and satire/parody protections. Not intended for commercial or serious use. \nUse responsibly, and in accordance with your platform’s content policy and applicable laws.\n\n## 🧪 Example Usage Prompt\n\n```text\nHunt3r Bid3n, cracked bathroom mirror selfie, harsh digital flash, shirtless, tired eyes, realistic cinematic lighting, messy background\n","type":"text"}],"tags":[{"text":"image","type":"highlight"},{"text":", lora, qwen, hunter-biden, generative-image, huwhitememes, Meme King Studio, Green Frog Labs, NSFW, text-to-image, base_model:Qwen/Qwen-Image, base_model:adapter:Qwen/Qwen-Image, license:apache-2.0, region:us","type":"text"}],"name":[{"text":"huwhitememes/laptophunterbiden_v1-qwen_image","type":"text"}],"fileName":[{"text":"README.md","type":"text"}]},"authorData":{"_id":"64e6956097b2582a5dbacc5a","avatarUrl":"https://cdn-avatars.huggingface.co/v1/production/uploads/64e6956097b2582a5dbacc5a/fvJe3nqEkcAUNiOCK1H46.png","fullname":"huwhitememes","name":"huwhitememes","type":"user","isPro":false,"isHf":false,"isHfAdmin":false,"isMod":false,"followerCount":25,"isUserFollowing":false}},{"repoId":"624f0eedc406a2741376a9f5","repoOwnerId":"624f0e05c8b211c193d324c0","isPrivate":false,"type":"model","likes":0,"isReadmeFile":true,"readmeStartLine":9,"updatedAt":1765222733470,"repoName":"FatimaFellowship-UpsideDown","repoOwner":"gymball","tags":"Image Classification, en, dataset:cifar100, license:unlicense, region:us","name":"gymball/FatimaFellowship-UpsideDown","fileName":"README.md","formatted":{"repoName":[{"text":"FatimaFellowship-UpsideDown","type":"text"}],"repoOwner":[{"text":"gymball","type":"text"}],"fileContent":[{"text":"\nThis repo contains a model that is capable of detecting upside ","type":"text"},{"text":"image","type":"highlight"},{"text":"s.\n\nThis is part of my submission for the Fatima Fellowship Selection Task.","type":"text"}],"tags":[{"text":"Image","type":"highlight"},{"text":" Classification, en, dataset:cifar100, license:unlicense, region:us","type":"text"}],"name":[{"text":"gymball/FatimaFellowship-UpsideDown","type":"text"}],"fileName":[{"text":"README.md","type":"text"}]},"authorData":{"_id":"624f0e05c8b211c193d324c0","avatarUrl":"/avatars/ee17bcf335f6608d4d065f0a22583c65.svg","fullname":"Chappidi Yoga Satwik","name":"gymball","type":"user","isPro":false,"isHf":false,"isHfAdmin":false,"isMod":false,"isUserFollowing":false}},{"repoId":"63430e6804d4ff28aeb7754a","repoOwnerId":"6103ed2248a651effc4e32ad","isPrivate":false,"type":"model","likes":0,"isReadmeFile":true,"readmeStartLine":11,"updatedAt":1765222783812,"repoName":"PP-HumanSegV1-Lite","repoOwner":"unography","tags":"image matting, image segmentation, en, license:apache-2.0, region:us","name":"unography/PP-HumanSegV1-Lite","fileName":"README.md","formatted":{"repoName":[{"text":"PP-HumanSegV1-Lite","type":"text"}],"repoOwner":[{"text":"unography","type":"text"}],"fileContent":[{"text":"PP-HumanSeg v1 model, released by [Paddle](https://github.com/PaddlePaddle/PaddleSeg/tree/release/2.6/contrib/PP-HumanSeg).\n\nTested on the [PP-HumanSeg-14K](https://github.com/PaddlePaddle/PaddleSeg/blob/release/2.6/contrib/PP-HumanSeg/paper.md) dataset.\n\n| Model Name | Best Input Shape | mIou(%) | Inference Time on Arm CPU(ms) | Modle Size(MB) |\n| --- | --- | --- | ---| --- |\n| PP-HumanSegV1-Lite | 398x224 | 93.60 | 29.68 | 2.3 |\n\n**Network Architecture**\n\nModel architecture named ConnectNet, which is suitable for real-time segmentation scenarios on the web or mobile.\n\n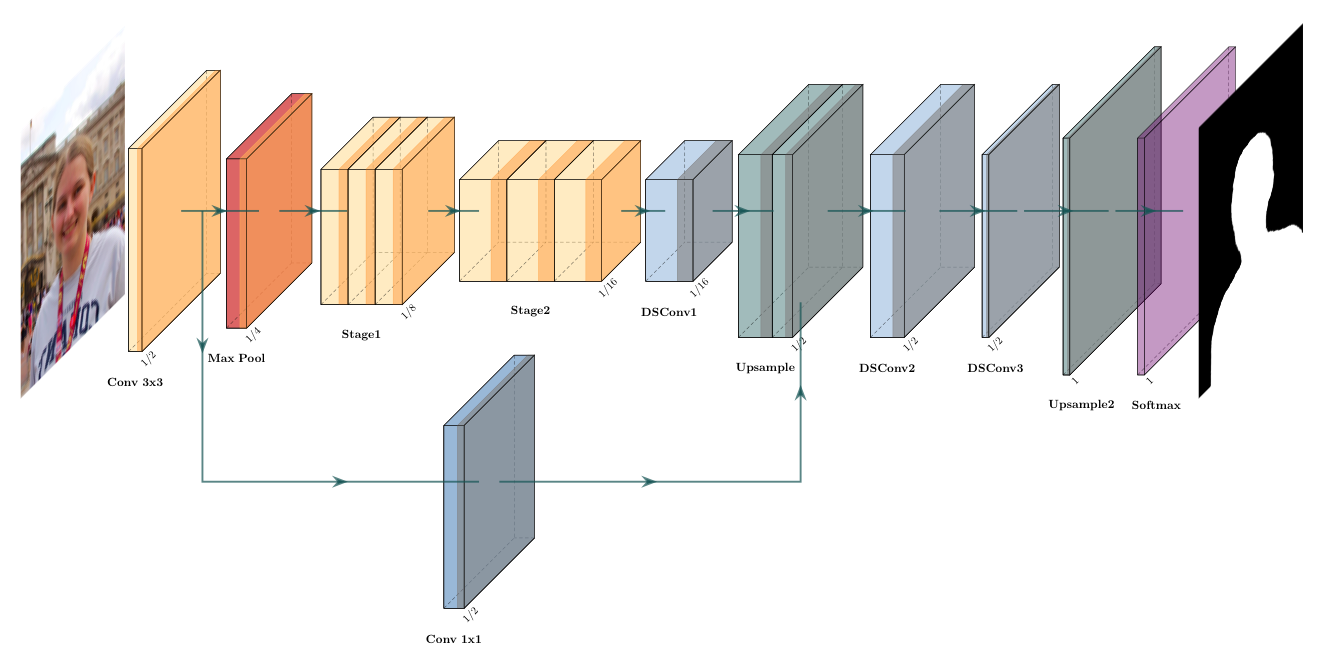\n\n[More details](https://github.com/unography/PaddleSeg/tree/release/2.6/configs/pp_humanseg_lite)","type":"text"}],"tags":[{"text":"image","type":"highlight"},{"text":" matting, ","type":"text"},{"text":"image","type":"highlight"},{"text":" segmentation, en, license:apache-2.0, region:us","type":"text"}],"name":[{"text":"unography/PP-HumanSegV1-Lite","type":"text"}],"fileName":[{"text":"README.md","type":"text"}]},"authorData":{"_id":"6103ed2248a651effc4e32ad","avatarUrl":"https://cdn-avatars.huggingface.co/v1/production/uploads/1662709588384-6103ed2248a651effc4e32ad.jpeg","fullname":"Dhruv K","name":"unography","type":"user","isPro":false,"isHf":false,"isHfAdmin":false,"isMod":false,"followerCount":15,"isUserFollowing":false}},{"repoId":"6342dfe207fa6ff0c2216e59","repoOwnerId":"6103ed2248a651effc4e32ad","isPrivate":false,"type":"model","likes":0,"isReadmeFile":true,"readmeStartLine":11,"updatedAt":1765222783981,"repoName":"PP-HumanSegV2-Lite","repoOwner":"unography","tags":"image matting, image segmentation, en, license:apache-2.0, region:us","name":"unography/PP-HumanSegV2-Lite","fileName":"README.md","formatted":{"repoName":[{"text":"PP-HumanSegV2-Lite","type":"text"}],"repoOwner":[{"text":"unography","type":"text"}],"fileContent":[{"text":"PP-HumanSeg v2 model, released by [Paddle](https://github.com/PaddlePaddle/PaddleSeg/tree/release/2.6/contrib/PP-HumanSeg).\n\nTested on the [PP-HumanSeg-14K](https://github.com/PaddlePaddle/PaddleSeg/blob/release/2.6/contrib/PP-HumanSeg/paper.md) dataset.\n\n| Model Name | Best Input Shape | mIou(%) | Inference Time on Arm CPU(ms) | Modle Size(MB) |\n| --- | --- | --- | ---| --- |\n| PP-HumanSegV2-Lite | 256x144 | 96.63 | 15.86 | 5.4 |","type":"text"}],"tags":[{"text":"image","type":"highlight"},{"text":" matting, ","type":"text"},{"text":"image","type":"highlight"},{"text":" segmentation, en, license:apache-2.0, region:us","type":"text"}],"name":[{"text":"unography/PP-HumanSegV2-Lite","type":"text"}],"fileName":[{"text":"README.md","type":"text"}]},"authorData":{"_id":"6103ed2248a651effc4e32ad","avatarUrl":"https://cdn-avatars.huggingface.co/v1/production/uploads/1662709588384-6103ed2248a651effc4e32ad.jpeg","fullname":"Dhruv K","name":"unography","type":"user","isPro":false,"isHf":false,"isHfAdmin":false,"isMod":false,"followerCount":15,"isUserFollowing":false}},{"repoId":"63a0bd103c8841cfe2ccc7de","repoOwnerId":"607feb037c746d01ecb19180","isPrivate":false,"type":"model","likes":0,"isReadmeFile":true,"readmeStartLine":11,"updatedAt":1765222823029,"repoName":"capdec_015","repoOwner":"johko","tags":"Image Captioning, image-to-text, en, dataset:MS-COCO, dataset:Flickr30k, arxiv:2211.00575, license:apache-2.0, region:us","name":"johko/capdec_015","fileName":"README.md","formatted":{"repoName":[{"text":"capdec_015","type":"text"}],"repoOwner":[{"text":"johko","type":"text"}],"fileContent":[{"text":"\n# CapDec - NoiseLevel: 0.015\n\n## Model Description\n\nThese are model weights originally provided by the authors of the paper [Text-Only Training for ","type":"text"},{"text":"Image","type":"highlight"},{"text":" Captioning using Noise-Injected CLIP](https://arxiv.org/pdf/2211.00575.pdf).\n\nTheir method aims to train CLIP with only text samples. Therefore they are injecting zero-mean Gaussian Noise into the text embeddings before decoding.\n\nIn their words:\n*Specifically, we assume that the visual embedding corresponding to a text embedding \nlies somewhere within a ball of small radius around the text embedding (see Fig. 1). \nWe would like all text embeddings in this ball to decode to the same caption,which should \nalso correspond to the visual content mapped to this ball. We implement this intuition by \nadding zero-mean Gaussian noise of STD to the text embedding before decoding it.*\n\nThe \"Noise Level\" of 0.015 is equivalent to the Noise Variance which is the square of the STD.\n\nThe reported metrics are results of a model with a Noise Variance of 0.016, which the authors unfortunately do not provide in their repository. \nThis model with a Noise Variance 0.015 is the closest available pre-trained model to their best model.\n\n## Datasets\nThe authors trained the model on MS-COCO and Flickr30k datasets.\n\n## Performance\nThe authors don't explicitly report the performance for this NoiseLevel but it can be estimated from the following figure from the original paper:\n\n","type":"text"}],"tags":[{"text":"Image","type":"highlight"},{"text":" Captioning, ","type":"text"},{"text":"image","type":"highlight"},{"text":"-to-text, en, dataset:MS-COCO, dataset:Flickr30k, arxiv:2211.00575, license:apache-2.0, region:us","type":"text"}],"name":[{"text":"johko/capdec_015","type":"text"}],"fileName":[{"text":"README.md","type":"text"}]},"authorData":{"_id":"607feb037c746d01ecb19180","avatarUrl":"https://cdn-avatars.huggingface.co/v1/production/uploads/607feb037c746d01ecb19180/qs3NO5v-Ej5UaKns8yFW8.jpeg","fullname":"Johannes Kolbe","name":"johko","type":"user","isPro":false,"isHf":false,"isHfAdmin":false,"isMod":false,"followerCount":66,"isUserFollowing":false}},{"repoId":"63be666f82f7306d0742ada1","repoOwnerId":"607feb037c746d01ecb19180","isPrivate":false,"type":"model","likes":0,"isReadmeFile":true,"readmeStartLine":11,"updatedAt":1765222838118,"repoName":"capdec_0","repoOwner":"johko","tags":"Image Captioning, image-to-text, en, dataset:MS-COCO, dataset:Flickr30k, arxiv:2211.00575, license:apache-2.0, region:us","name":"johko/capdec_0","fileName":"README.md","formatted":{"repoName":[{"text":"capdec_0","type":"text"}],"repoOwner":[{"text":"johko","type":"text"}],"fileContent":[{"text":"\n# CapDec - NoiseLevel: 0\n\n## Model Description\n\nThese are model weights originally provided by the authors of the paper [Text-Only Training for ","type":"text"},{"text":"Image","type":"highlight"},{"text":" Captioning using Noise-Injected CLIP](https://arxiv.org/pdf/2211.00575.pdf).\n\nTheir method aims to train CLIP with only text samples. Therefore they are injecting zero-mean Gaussian Noise into the text embeddings before decoding.\n\nIn their words:\n*Specifically, we assume that the visual embedding corresponding to a text embedding \nlies somewhere within a ball of small radius around the text embedding (see Fig. 1). \nWe would like all text embeddings in this ball to decode to the same caption,which should \nalso correspond to the visual content mapped to this ball. We implement this intuition by \nadding zero-mean Gaussian noise of STD to the text embedding before decoding it.*\n\nThe \"Noise Level\" of 0 is equivalent to the Noise Variance which is the square of the STD.\n\nThe reported metrics are results of a model with a Noise Variance of 0.016, which the authors unfortunately do not provide in their repository. \n\n## Datasets\nThe authors trained the model on MS-COCO and Flickr30k datasets.\n\n## Performance\nThe authors don't explicitly report the performance for this NoiseLevel but it can be estimated from the following figure from the original paper:\n","type":"text"}],"tags":[{"text":"Image","type":"highlight"},{"text":" Captioning, ","type":"text"},{"text":"image","type":"highlight"},{"text":"-to-text, en, dataset:MS-COCO, dataset:Flickr30k, arxiv:2211.00575, license:apache-2.0, region:us","type":"text"}],"name":[{"text":"johko/capdec_0","type":"text"}],"fileName":[{"text":"README.md","type":"text"}]},"authorData":{"_id":"607feb037c746d01ecb19180","avatarUrl":"https://cdn-avatars.huggingface.co/v1/production/uploads/607feb037c746d01ecb19180/qs3NO5v-Ej5UaKns8yFW8.jpeg","fullname":"Johannes Kolbe","name":"johko","type":"user","isPro":false,"isHf":false,"isHfAdmin":false,"isMod":false,"followerCount":66,"isUserFollowing":false}},{"repoId":"63be67b1a2f6fcbfa7eed479","repoOwnerId":"607feb037c746d01ecb19180","isPrivate":false,"type":"model","likes":0,"isReadmeFile":true,"readmeStartLine":11,"updatedAt":1765222841894,"repoName":"capdec_001","repoOwner":"johko","tags":"Image Captioning, image-to-text, en, dataset:MS-COCO, dataset:Flickr30k, arxiv:2211.00575, license:apache-2.0, region:us","name":"johko/capdec_001","fileName":"README.md","formatted":{"repoName":[{"text":"capdec_001","type":"text"}],"repoOwner":[{"text":"johko","type":"text"}],"fileContent":[{"text":"\n# CapDec - NoiseLevel: 0.001\n\n## Model Description\n\nThese are model weights originally provided by the authors of the paper [Text-Only Training for ","type":"text"},{"text":"Image","type":"highlight"},{"text":" Captioning using Noise-Injected CLIP](https://arxiv.org/pdf/2211.00575.pdf).\n\nTheir method aims to train CLIP with only text samples. Therefore they are injecting zero-mean Gaussian Noise into the text embeddings before decoding.\n\nIn their words:\n*Specifically, we assume that the visual embedding corresponding to a text embedding \nlies somewhere within a ball of small radius around the text embedding (see Fig. 1). \nWe would like all text embeddings in this ball to decode to the same caption,which should \nalso correspond to the visual content mapped to this ball. We implement this intuition by \nadding zero-mean Gaussian noise of STD to the text embedding before decoding it.*\n\nThe \"Noise Level\" of 0.001 is equivalent to the Noise Variance which is the square of the STD.\n\nThe reported metrics are results of a model with a Noise Variance of 0.016, which the authors unfortunately do not provide in their repository. \n\n## Datasets\nThe authors trained the model on MS-COCO and Flickr30k datasets.\n\n## Performance\nThe authors don't explicitly report the performance for this NoiseLevel but it can be estimated from the following figure from the original paper:\n","type":"text"}],"tags":[{"text":"Image","type":"highlight"},{"text":" Captioning, ","type":"text"},{"text":"image","type":"highlight"},{"text":"-to-text, en, dataset:MS-COCO, dataset:Flickr30k, arxiv:2211.00575, license:apache-2.0, region:us","type":"text"}],"name":[{"text":"johko/capdec_001","type":"text"}],"fileName":[{"text":"README.md","type":"text"}]},"authorData":{"_id":"607feb037c746d01ecb19180","avatarUrl":"https://cdn-avatars.huggingface.co/v1/production/uploads/607feb037c746d01ecb19180/qs3NO5v-Ej5UaKns8yFW8.jpeg","fullname":"Johannes Kolbe","name":"johko","type":"user","isPro":false,"isHf":false,"isHfAdmin":false,"isMod":false,"followerCount":66,"isUserFollowing":false}},{"repoId":"63bfd9d4c42fb2d7f8638c7a","repoOwnerId":"607feb037c746d01ecb19180","isPrivate":false,"type":"model","likes":0,"isReadmeFile":true,"readmeStartLine":11,"updatedAt":1765222838053,"repoName":"capdec_005","repoOwner":"johko","tags":"Image Captioning, image-to-text, en, dataset:MS-COCO, dataset:Flickr30k, arxiv:2211.00575, license:apache-2.0, region:us","name":"johko/capdec_005","fileName":"README.md","formatted":{"repoName":[{"text":"capdec_005","type":"text"}],"repoOwner":[{"text":"johko","type":"text"}],"fileContent":[{"text":"\n# CapDec - NoiseLevel: 0.005\n\n## Model Description\n\nThese are model weights originally provided by the authors of the paper [Text-Only Training for ","type":"text"},{"text":"Image","type":"highlight"},{"text":" Captioning using Noise-Injected CLIP](https://arxiv.org/pdf/2211.00575.pdf).\n\nTheir method aims to train CLIP with only text samples. Therefore they are injecting zero-mean Gaussian Noise into the text embeddings before decoding.\n\nIn their words:\n*Specifically, we assume that the visual embedding corresponding to a text embedding \nlies somewhere within a ball of small radius around the text embedding (see Fig. 1). \nWe would like all text embeddings in this ball to decode to the same caption,which should \nalso correspond to the visual content mapped to this ball. We implement this intuition by \nadding zero-mean Gaussian noise of STD to the text embedding before decoding it.*\n\nThe \"Noise Level\" of 0.005 is equivalent to the Noise Variance which is the square of the STD.\n\nThe reported metrics are results of a model with a Noise Variance of 0.016, which the authors unfortunately do not provide in their repository. \n\n## Datasets\nThe authors trained the model on MS-COCO and Flickr30k datasets.\n\n## Performance\nThe authors don't explicitly report the performance for this NoiseLevel but it can be estimated from the following figure from the original paper:\n","type":"text"}],"tags":[{"text":"Image","type":"highlight"},{"text":" Captioning, ","type":"text"},{"text":"image","type":"highlight"},{"text":"-to-text, en, dataset:MS-COCO, dataset:Flickr30k, arxiv:2211.00575, license:apache-2.0, region:us","type":"text"}],"name":[{"text":"johko/capdec_005","type":"text"}],"fileName":[{"text":"README.md","type":"text"}]},"authorData":{"_id":"607feb037c746d01ecb19180","avatarUrl":"https://cdn-avatars.huggingface.co/v1/production/uploads/607feb037c746d01ecb19180/qs3NO5v-Ej5UaKns8yFW8.jpeg","fullname":"Johannes Kolbe","name":"johko","type":"user","isPro":false,"isHf":false,"isHfAdmin":false,"isMod":false,"followerCount":66,"isUserFollowing":false}},{"repoId":"63bfda5c81067568a58b4b93","repoOwnerId":"607feb037c746d01ecb19180","isPrivate":false,"type":"model","likes":0,"isReadmeFile":true,"readmeStartLine":11,"updatedAt":1765222838618,"repoName":"capdec_025","repoOwner":"johko","tags":"Image Captioning, image-to-text, en, dataset:MS-COCO, dataset:Flickr30k, arxiv:2211.00575, license:apache-2.0, region:us","name":"johko/capdec_025","fileName":"README.md","formatted":{"repoName":[{"text":"capdec_025","type":"text"}],"repoOwner":[{"text":"johko","type":"text"}],"fileContent":[{"text":"\n# CapDec - NoiseLevel: 0.025\n\n## Model Description\n\nThese are model weights originally provided by the authors of the paper [Text-Only Training for ","type":"text"},{"text":"Image","type":"highlight"},{"text":" Captioning using Noise-Injected CLIP](https://arxiv.org/pdf/2211.00575.pdf).\n\nTheir method aims to train CLIP with only text samples. Therefore they are injecting zero-mean Gaussian Noise into the text embeddings before decoding.\n\nIn their words:\n*Specifically, we assume that the visual embedding corresponding to a text embedding \nlies somewhere within a ball of small radius around the text embedding (see Fig. 1). \nWe would like all text embeddings in this ball to decode to the same caption,which should \nalso correspond to the visual content mapped to this ball. We implement this intuition by \nadding zero-mean Gaussian noise of STD to the text embedding before decoding it.*\n\nThe \"Noise Level\" of 0.025 is equivalent to the Noise Variance which is the square of the STD.\n\nThe reported metrics are results of a model with a Noise Variance of 0.016, which the authors unfortunately do not provide in their repository. \n\n## Datasets\nThe authors trained the model on MS-COCO and Flickr30k datasets.\n\n## Performance\nThe authors don't explicitly report the performance for this NoiseLevel but it can be estimated from the following figure from the original paper:\n","type":"text"}],"tags":[{"text":"Image","type":"highlight"},{"text":" Captioning, ","type":"text"},{"text":"image","type":"highlight"},{"text":"-to-text, en, dataset:MS-COCO, dataset:Flickr30k, arxiv:2211.00575, license:apache-2.0, region:us","type":"text"}],"name":[{"text":"johko/capdec_025","type":"text"}],"fileName":[{"text":"README.md","type":"text"}]},"authorData":{"_id":"607feb037c746d01ecb19180","avatarUrl":"https://cdn-avatars.huggingface.co/v1/production/uploads/607feb037c746d01ecb19180/qs3NO5v-Ej5UaKns8yFW8.jpeg","fullname":"Johannes Kolbe","name":"johko","type":"user","isPro":false,"isHf":false,"isHfAdmin":false,"isMod":false,"followerCount":66,"isUserFollowing":false}}]}