

Commit
·
4a90298
1
Parent(s):
04736a9
Audio transcription examples added and model names changed
Browse files- .gitattributes +4 -0
- README.md +76 -9
- audio_samples/example1.wav +3 -0
- audio_samples/example2.wav +3 -0
- audio_samples/example3.wav +3 -0
- images/cer.png +0 -0
- images/wer.png +0 -0
.gitattributes
CHANGED
|
@@ -37,3 +37,7 @@ unigrams.txt filter=lfs diff=lfs merge=lfs -text
|
|
| 37 |
language_model/3gram.bin filter=lfs diff=lfs merge=lfs -text
|
| 38 |
language_model/attrs.json filter=lfs diff=lfs merge=lfs -text
|
| 39 |
language_model/unigrams.txt filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 37 |
language_model/3gram.bin filter=lfs diff=lfs merge=lfs -text
|
| 38 |
language_model/attrs.json filter=lfs diff=lfs merge=lfs -text
|
| 39 |
language_model/unigrams.txt filter=lfs diff=lfs merge=lfs -text
|
| 40 |
+
audio_samples/example1.wav filter=lfs diff=lfs merge=lfs -text
|
| 41 |
+
audio_samples/example2.wav filter=lfs diff=lfs merge=lfs -text
|
| 42 |
+
audio_samples/example3.wav filter=lfs diff=lfs merge=lfs -text
|
| 43 |
+
audio_samples/example4.wav filter=lfs diff=lfs merge=lfs -text
|
README.md
CHANGED
|
@@ -53,13 +53,80 @@ Next you can use the model using the `transformers` Python package as follows:
|
|
| 53 |
{'text': 'your transcription'}
|
| 54 |
```
|
| 55 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 56 |
## Model Details
|
| 57 |
|
| 58 |
Wav2Vec2 is a state-of-the-art model architecture for speech recognition, leveraging self-supervised learning from raw audio data. The pre-trained [Wav2Vec2-XLS-R-300M](facebook/wav2vec2-xls-r-300m) has been fine-tuned for automatic speech recognition with the [CoRal-v2 dataset](https://huggingface.co/datasets/CoRal-dataset/coral-v2/tree/main) dataset to enhance its performance in recognizing Danish speech with consideration to different dialects. The model was trained for 30K steps using the training setup in the [CoRaL repository](https://github.com/alexandrainst/coral/tree) by running:
|
| 59 |
```
|
| 60 |
python src/scripts/finetune_asr_model.py model=wav2vec2-small max_steps=30000 datasets.coral_conversation_internal.id=CoRal-dataset/coral-v2 datasets.coral_readaloud_internal.id=CoRal-dataset/coral-v2
|
| 61 |
```
|
| 62 |
-
The model is evaluated using a Language Model (LM) as post-processing. The utilized LM is the one trained and used by [alexandrainst/roest-315m](https://huggingface.co/alexandrainst/roest-315m).
|
| 63 |
## Dataset
|
| 64 |
|
| 65 |
### [CoRal-v2](https://huggingface.co/datasets/CoRal-dataset/coral-v2/tree/main)
|
|
@@ -84,8 +151,8 @@ The model was evaluated using the following metrics:
|
|
| 84 |
| :----------------------------------------------------------------------------------------------- | -------------------: | --------------------------: | --------------------------------------------------------------------------------------: | --------------------------------------------------------------------------------------: |
|
| 85 |
| [CoRal-dataset/roest-wav2vec2-315M-v2](https://huggingface.co/CoRal-dataset/roest-whisper-large) | 315M | Read-aloud and conversation | 6.5% ± 0.2% | 16.3% ± 0.4% |
|
| 86 |
| [CoRal-dataset/roest-whisper-large-v2](https://huggingface.co/CoRal-dataset/roest-whisper-large) | 1540M | Read-aloud and conversation | 5.3% ± 0.2% | 12.0% ± 0.4% |
|
| 87 |
-
| [Alvenir/
|
| 88 |
-
| [alexandrainst/roest-
|
| 89 |
| [mhenrichsen/hviske-v2](https://huggingface.co/syvai/hviske-v2) | 1540M | Read-aloud | 4.7% ± 0.2% | 11.8% ± 0.3% |
|
| 90 |
| [openai/whisper-large-v3](https://hf.co/openai/whisper-large-v3) | 1540M | - | 11.4% ± 0.3% | 28.3% ± 0.6% |
|
| 91 |
|
|
@@ -97,7 +164,7 @@ The model was evaluated using the following metrics:
|
|
| 97 |
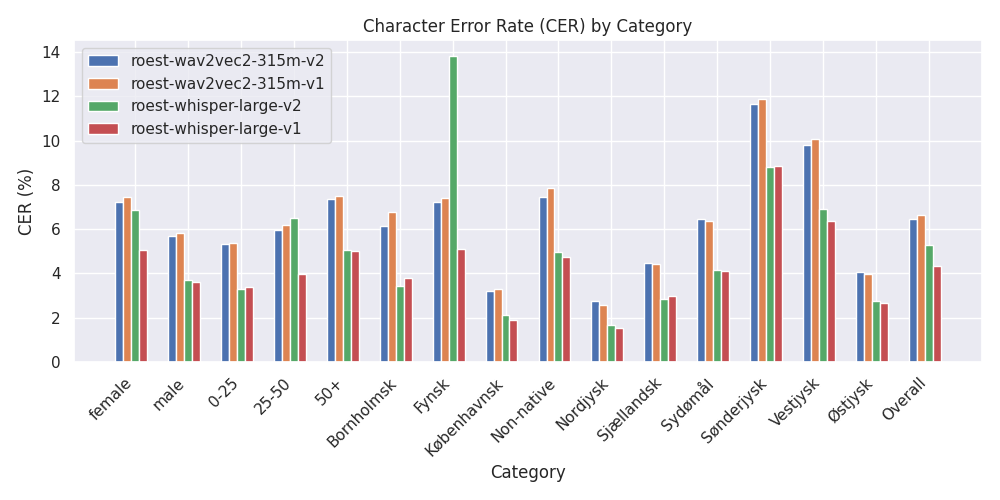
<img src="https://huggingface.co/CoRal-dataset/roest-wav2vec2-315m-v2/resolve/main/images/cer.png">
|
| 98 |
|
| 99 |
### Table CER scores in % of evaluation across demographics on the CoRal test data
|
| 100 |
-
| Category | roest-wav2vec2-315m-v2 | roest-315m | roest-whisper-large-v2 |
|
| 101 |
|:---:|:---:|:---:|:---:|:---:|
|
| 102 |
| female | 7.2 | 7.4 | 6.9 | 5.1 |
|
| 103 |
| male | 5.7 | 5.8 | 3.7 | 3.6 |
|
|
@@ -117,7 +184,7 @@ The model was evaluated using the following metrics:
|
|
| 117 |
| Overall | 6.5 | 6.6 | 5.3 | 4.3 |
|
| 118 |
|
| 119 |
### Table WER scores in % of evaluation across demographics on the CoRal test data
|
| 120 |
-
| Category | roest-wav2vec2-315m-v2 | roest-315m | roest-whisper-large-v2 |
|
| 121 |
|:---:|:---:|:---:|:---:|:---:|
|
| 122 |
| female | 17.7 | 18.5 | 14.2 | 11.5 |
|
| 123 |
| male | 14.9 | 15.5 | 9.9 | 9.4 |
|
|
@@ -138,19 +205,19 @@ The model was evaluated using the following metrics:
|
|
| 138 |
|
| 139 |
|
| 140 |
### Roest-wav2vec2-315M with and without language model
|
| 141 |
-
The inclusion of a post-processing language model can affect the performance significantly. The Roest-v1 and Roest-v2 models are using the same Language Model (LM). The utilized LM is the one trained and used by [alexandrainst/roest-315m](https://huggingface.co/alexandrainst/roest-315m).
|
| 142 |
|
| 143 |
| Model | Number of parameters | Finetuned on data of type | Postprocessed with Language Model | [CoRal](https://huggingface.co/datasets/alexandrainst/coral/viewer/read_aloud/test) CER | [CoRal](https://huggingface.co/datasets/alexandrainst/coral/viewer/read_aloud/test) WER |
|
| 144 |
| :-------------------------------------------------------------------------------------------- | -------------------: | --------------------------: | --------------------------------: | --------------------------------------------------------------------------------------: | --------------------------------------------------------------------------------------: |
|
| 145 |
| [CoRal-dataset/roest-wav2vec2-315M-v2](https://huggingface.co/CoRal-dataset/roest-wav2vec2-315m-v2) | 315M | Read-aloud and conversation | Yes | **6.5% ± 0.2%** | **16.3% ± 0.4%** |
|
| 146 |
| [CoRal-dataset/roest-wav2vec2-315M-v2](https://huggingface.co/CoRal-dataset/roest-wav2vec2-315m-v2) | 315M | Read-aloud and conversation | No | 8.2% ± 0.2% | 25.1% ± 0.4% |
|
| 147 |
-
| [alexandrainst/roest-315m](https://huggingface.co/alexandrainst/roest-315m) | 315M | Read-aloud | Yes | 6.6% ± 0.2% | 17.0% ± 0.4% |
|
| 148 |
-
| [alexandrainst/roest-315m](https://huggingface.co/alexandrainst/roest-315m) | 315M | Read-aloud | No | 8.6% ± 0.2% | 26.3% ± 0.5% |
|
| 149 |
|
| 150 |
### Detailed Roest-wav2vec2-315M with and without language model on different dialects
|
| 151 |
Here are the results of the model on different danish dialects in the test set:
|
| 152 |
|
| 153 |
-
| | Roest-
|
| 154 |
|-------------|---------|---------|---------|---------|---------|---------|---------|---------|
|
| 155 |
| LM | No | | Yes | | No | | Yes | |
|
| 156 |
|-------------|---------|---------|---------|---------|---------|---------|---------|---------|
|
|
|
|
| 53 |
{'text': 'your transcription'}
|
| 54 |
```
|
| 55 |
|
| 56 |
+
## Transcription examples
|
| 57 |
+
|
| 58 |
+
### Example 1
|
| 59 |
+
<audio controls>
|
| 60 |
+
<source src="https://huggingface.co/CoRal-dataset/roest-wav2vec2-315m-v2/resolve/main/audio_samples/example1.wav" type="audio/wav">
|
| 61 |
+
Your browser does not support the audio tag.
|
| 62 |
+
</audio>
|
| 63 |
+
|
| 64 |
+
**Dialect:** Vestjysk
|
| 65 |
+
|
| 66 |
+
**Transcription:** det blev til yderlig ti mål i den første sæson på trods af en position som back
|
| 67 |
+
|
| 68 |
+
**Target transcription:** det blev til yderligere ti mål i den første sæson på trods af en position som back
|
| 69 |
+
|
| 70 |
+
**CER:** 3.7%
|
| 71 |
+
|
| 72 |
+
**WER:** 5.9%
|
| 73 |
+
|
| 74 |
+
### Example 2
|
| 75 |
+
<audio controls>
|
| 76 |
+
<source src="https://huggingface.co/CoRal-dataset/roest-wav2vec2-315m-v2/resolve/main/audio_samples/example2.wav" type="audio/wav">
|
| 77 |
+
Your browser does not support the audio tag.
|
| 78 |
+
</audio>
|
| 79 |
+
|
| 80 |
+
**Dialect:** Sønderjysk
|
| 81 |
+
|
| 82 |
+
**Transcription:** en arkitektoniske udformning af pladser forslagene iver benzen
|
| 83 |
+
|
| 84 |
+
**Target transcription:** den arkitektoniske udformning af pladsen er forestået af ivar bentsen
|
| 85 |
+
|
| 86 |
+
**CER:** 20.3%
|
| 87 |
+
|
| 88 |
+
**WER:** 60.0%
|
| 89 |
+
|
| 90 |
+
### Example 3
|
| 91 |
+
<audio controls>
|
| 92 |
+
<source src="https://huggingface.co/CoRal-dataset/roest-wav2vec2-315m-v2/resolve/main/audio_samples/example3.wav" type="audio/wav">
|
| 93 |
+
Your browser does not support the audio tag.
|
| 94 |
+
</audio>
|
| 95 |
+
|
| 96 |
+
**Dialect:** Nordsjællandsk
|
| 97 |
+
|
| 98 |
+
**Transcription:** østrig og ungarn samarbejder om søen gennem den østrigske og ungarske vandkommission
|
| 99 |
+
|
| 100 |
+
**Target transcription:** østrig og ungarn samarbejder om søen gennem den østrigske og ungarske vandkommission
|
| 101 |
+
|
| 102 |
+
**CER:** 0.0%
|
| 103 |
+
|
| 104 |
+
**WER:** 0.0%
|
| 105 |
+
|
| 106 |
+
### Example 4
|
| 107 |
+
<audio controls>
|
| 108 |
+
<source src="https://huggingface.co/CoRal-dataset/roest-wav2vec2-315m-v2/resolve/main/audio_samples/example4.wav" type="audio/wav">
|
| 109 |
+
Your browser does not support the audio tag.
|
| 110 |
+
</audio>
|
| 111 |
+
|
| 112 |
+
**Dialect:** Lollandsk
|
| 113 |
+
|
| 114 |
+
**Transcription:** det er produceret af thomas helme og indspillede i easy sound recording studio i københavn
|
| 115 |
+
|
| 116 |
+
**Target transcription:** det er produceret af thomas helmig og indspillet i easy sound recording studio i københavn
|
| 117 |
+
|
| 118 |
+
**CER:** 4.4%
|
| 119 |
+
|
| 120 |
+
**WER:** 13.3%
|
| 121 |
+
|
| 122 |
+
|
| 123 |
## Model Details
|
| 124 |
|
| 125 |
Wav2Vec2 is a state-of-the-art model architecture for speech recognition, leveraging self-supervised learning from raw audio data. The pre-trained [Wav2Vec2-XLS-R-300M](facebook/wav2vec2-xls-r-300m) has been fine-tuned for automatic speech recognition with the [CoRal-v2 dataset](https://huggingface.co/datasets/CoRal-dataset/coral-v2/tree/main) dataset to enhance its performance in recognizing Danish speech with consideration to different dialects. The model was trained for 30K steps using the training setup in the [CoRaL repository](https://github.com/alexandrainst/coral/tree) by running:
|
| 126 |
```
|
| 127 |
python src/scripts/finetune_asr_model.py model=wav2vec2-small max_steps=30000 datasets.coral_conversation_internal.id=CoRal-dataset/coral-v2 datasets.coral_readaloud_internal.id=CoRal-dataset/coral-v2
|
| 128 |
```
|
| 129 |
+
The model is evaluated using a Language Model (LM) as post-processing. The utilized LM is the one trained and used by [alexandrainst/roest-wav2vec2-315m-v1](https://huggingface.co/alexandrainst/roest-315m).
|
| 130 |
## Dataset
|
| 131 |
|
| 132 |
### [CoRal-v2](https://huggingface.co/datasets/CoRal-dataset/coral-v2/tree/main)
|
|
|
|
| 151 |
| :----------------------------------------------------------------------------------------------- | -------------------: | --------------------------: | --------------------------------------------------------------------------------------: | --------------------------------------------------------------------------------------: |
|
| 152 |
| [CoRal-dataset/roest-wav2vec2-315M-v2](https://huggingface.co/CoRal-dataset/roest-whisper-large) | 315M | Read-aloud and conversation | 6.5% ± 0.2% | 16.3% ± 0.4% |
|
| 153 |
| [CoRal-dataset/roest-whisper-large-v2](https://huggingface.co/CoRal-dataset/roest-whisper-large) | 1540M | Read-aloud and conversation | 5.3% ± 0.2% | 12.0% ± 0.4% |
|
| 154 |
+
| [Alvenir/roest-whisper-large-v1](https://huggingface.co/Alvenir/coral-1-whisper-large) | 1540M | Read-aloud | **4.3% ± 0.2%** | **10.4% ± 0.3%** |
|
| 155 |
+
| [alexandrainst/roest-wav2vec2-315M-v1](https://huggingface.co/alexandrainst/roest-315m) | 315M | Read-aloud | 6.6% ± 0.2% | 17.0% ± 0.4% |
|
| 156 |
| [mhenrichsen/hviske-v2](https://huggingface.co/syvai/hviske-v2) | 1540M | Read-aloud | 4.7% ± 0.2% | 11.8% ± 0.3% |
|
| 157 |
| [openai/whisper-large-v3](https://hf.co/openai/whisper-large-v3) | 1540M | - | 11.4% ± 0.3% | 28.3% ± 0.6% |
|
| 158 |
|
|
|
|
| 164 |
<img src="https://huggingface.co/CoRal-dataset/roest-wav2vec2-315m-v2/resolve/main/images/cer.png">
|
| 165 |
|
| 166 |
### Table CER scores in % of evaluation across demographics on the CoRal test data
|
| 167 |
+
| Category | roest-wav2vec2-315m-v2 | roest-wav2vec2-315m-v1 | roest-whisper-large-v2 | roest-whisper-large-v1 |
|
| 168 |
|:---:|:---:|:---:|:---:|:---:|
|
| 169 |
| female | 7.2 | 7.4 | 6.9 | 5.1 |
|
| 170 |
| male | 5.7 | 5.8 | 3.7 | 3.6 |
|
|
|
|
| 184 |
| Overall | 6.5 | 6.6 | 5.3 | 4.3 |
|
| 185 |
|
| 186 |
### Table WER scores in % of evaluation across demographics on the CoRal test data
|
| 187 |
+
| Category | roest-wav2vec2-315m-v2 | roest-wav2vec2-315m-v1 | roest-whisper-large-v2 | roest-whisper-large-v1 |
|
| 188 |
|:---:|:---:|:---:|:---:|:---:|
|
| 189 |
| female | 17.7 | 18.5 | 14.2 | 11.5 |
|
| 190 |
| male | 14.9 | 15.5 | 9.9 | 9.4 |
|
|
|
|
| 205 |
|
| 206 |
|
| 207 |
### Roest-wav2vec2-315M with and without language model
|
| 208 |
+
The inclusion of a post-processing language model can affect the performance significantly. The Roest-v1 and Roest-v2 models are using the same Language Model (LM). The utilized LM is the one trained and used by [alexandrainst/roest-wav2vec2-315m-v1](https://huggingface.co/alexandrainst/roest-315m).
|
| 209 |
|
| 210 |
| Model | Number of parameters | Finetuned on data of type | Postprocessed with Language Model | [CoRal](https://huggingface.co/datasets/alexandrainst/coral/viewer/read_aloud/test) CER | [CoRal](https://huggingface.co/datasets/alexandrainst/coral/viewer/read_aloud/test) WER |
|
| 211 |
| :-------------------------------------------------------------------------------------------- | -------------------: | --------------------------: | --------------------------------: | --------------------------------------------------------------------------------------: | --------------------------------------------------------------------------------------: |
|
| 212 |
| [CoRal-dataset/roest-wav2vec2-315M-v2](https://huggingface.co/CoRal-dataset/roest-wav2vec2-315m-v2) | 315M | Read-aloud and conversation | Yes | **6.5% ± 0.2%** | **16.3% ± 0.4%** |
|
| 213 |
| [CoRal-dataset/roest-wav2vec2-315M-v2](https://huggingface.co/CoRal-dataset/roest-wav2vec2-315m-v2) | 315M | Read-aloud and conversation | No | 8.2% ± 0.2% | 25.1% ± 0.4% |
|
| 214 |
+
| [alexandrainst/roest-wav2vec2-315m-v1](https://huggingface.co/alexandrainst/roest-315m) | 315M | Read-aloud | Yes | 6.6% ± 0.2% | 17.0% ± 0.4% |
|
| 215 |
+
| [alexandrainst/roest-wav2vec2-315m-v1](https://huggingface.co/alexandrainst/roest-315m) | 315M | Read-aloud | No | 8.6% ± 0.2% | 26.3% ± 0.5% |
|
| 216 |
|
| 217 |
### Detailed Roest-wav2vec2-315M with and without language model on different dialects
|
| 218 |
Here are the results of the model on different danish dialects in the test set:
|
| 219 |
|
| 220 |
+
| | Roest-v1 | | Roest-v1 | | Roest-v2 | | Roest-v2 | |
|
| 221 |
|-------------|---------|---------|---------|---------|---------|---------|---------|---------|
|
| 222 |
| LM | No | | Yes | | No | | Yes | |
|
| 223 |
|-------------|---------|---------|---------|---------|---------|---------|---------|---------|
|
audio_samples/example1.wav
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:97be8c695d4c6debdd4096cea9400468992ecf27743f313ff8e988271c9b6aae
|
| 3 |
+
size 529978
|
audio_samples/example2.wav
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:e97d6c5d5999f8f2c6eed1f2847f4dae0006e7025148a17503b3f836c5f4a57a
|
| 3 |
+
size 249658
|
audio_samples/example3.wav
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:5e8c8870082c39d13d1f2800cefb971bd9d56667d1e4437d05feee8e3900e18a
|
| 3 |
+
size 361018
|
images/cer.png
CHANGED

|
|
images/wer.png
CHANGED

|

|